| ||||
|
You may redistribute this newsletter for non-commercial purposes. For commercial use contact jack@ganssle.com. To subscribe or unsubscribe go here or drop Jack an email. |
||||
| Contents | ||||
| Editor's Notes | ||||
Tip for sending me email: My email filters are super aggressive and I no longer look at the spam mailbox. If you include the phrase "embedded" in the subject line your email will wend its weighty way to me. The Embedded Online Conference has concluded, but the folks there have generously opened up my keynote for free access. You do have to register, but feel free to see the session here. Bob Paddock sent this:
Bob found that an open-source version of the Z80 is coming out: https://www.eenewseurope.com/en/open-source-z80-to-replace-end-of-line-chip/ |
||||
| Quotes and Thoughts | ||||
|
“The competent programmer is fully aware of the strictly limited size of his own skull; therefore he approaches the programming task in full humility, and among other things he avoids clever tricks like the plague.” -- Dijkstra |
||||
| Tools and Tips | ||||
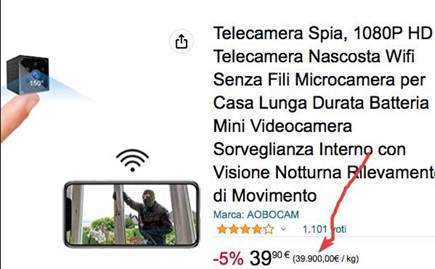
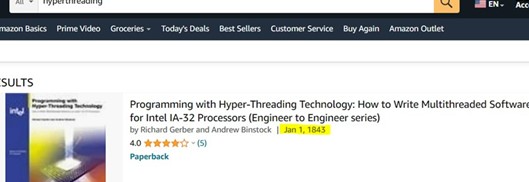
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past. Also from Bob Paddock:
|
||||
| Failures in the Field | ||||
|
Daniel McBrearty has an interesting story:
|
||||
| Slowing Down to Speed Up | ||||
|
"Faster development tools may paradoxically increase the time to complete programming tasks." - Phillip Armour This has been my observation. In ancient times programmers keyed their programs, one statement per card, on punched cards, which were then submitted to the computer center. A typical run had a 24 hour turnaround. No one could afford dumb mistakes with that cycle time, so the notion of "playing computer" surfaced. The developer would get a listing and execute the code in his head, very carefully, looking for mistakes. Fast forward to today and the situation is very different. You're sitting there, feet up on the desk, IR keyboard at hand and lots of windows open on the 32" monitor. Run into a bug, and maybe changing that ">=" to ">" will fix it. Make a change and in a few seconds you're debugging again. If lucky, the patch won't work. Did you isolate the real problem with those three seconds of thought? How do you know? We need debug logs. When a problem surfaces, write it down. Write down what you learn from trace data, single-stepping, and other debugging strategies. When the fix is clear, don't implement it. Write it down, first, and then key it into the IDE. Now, with 30 seconds worth of thought, the odds of getting a correct fix increase. Have you ever watched a developer spend days chasing a bug? Inevitably he'll forget what tests he's run, what variables he's looked at, and repeat the tests. A debug log makes this impossible. Finally, go over your log every 6-12 months. Patterns will appear. Identify those, so you don't make the same mistakes again. |
||||
| Failure of the Week | ||||
Farbizio Bernardini sent this: This is from Ian McCutcheon:
Have you submitted a Failure of the Week? I'm getting a ton of these and yours was added to the queue. |
||||
| Jobs! | ||||
|
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intent of this newsletter. Please keep it to 100 words. There is no charge for a job ad.
|
||||
| Joke For The Week | ||||
These jokes are archived here. From Bob Paddock: This is from the Intel 8048 manual in 1977: "A well placed underscore can make the difference between a s_exchange and a sex_change." |
||||
| About The Embedded Muse | ||||
|
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. |