| ||||
|
You may redistribute this newsletter for non-commercial purposes. For commercial use contact jack@ganssle.com. To subscribe or unsubscribe go here or drop Jack an email. |
||||
| Contents | ||||
| Editor's Notes | ||||
Tip for sending me email: My email filters are super aggressive and I no longer look at the spam mailbox. If you include the phrase "embedded" in the subject line your email will wend its weighty way to me. |
||||
| Quotes and Thoughts | ||||
|
"Those who want really reliable software will discover that they must find means of avoiding the majority of bugs to start with, and as a result the programming process will become cheaper. If you want more effective programmers, you will discover that they should not waste their time debugging, they should not introduce the bugs to start with." - Dijkstra |
||||
| Tools and Tips | ||||
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past. Here's a good article about using the Mongoose networking library with MicroPython. |
||||
| C to C++ | ||||
|
John Carter has some tips on going from C to C++:
Vlad Z's take on C is:
I have to agree that hardware support, in these days of nearly-free transistors, is a must. Why most/all processors don't include some sort of memory management unit is beyond me. Vlad mentions that he remembers when one could not blow the stack. I remember the 8008, whose stack was in hardware, and which was a mere 7 levels deep. We blew that all the time! |
||||
| On Bugs | ||||
|
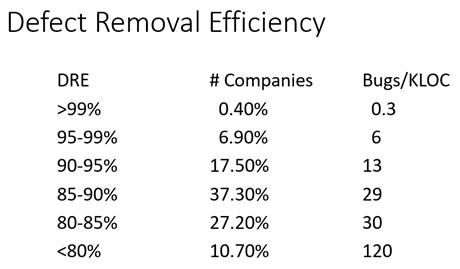
Engineering is all about numbers, and the numbers can reveal some startling facts. This is data from " Software Quality in 2011: A survey of the State of the Art" by Capers Jones, combined with my data for embedded. Though Jones' data is oldish, I see no evidence that the numbers have changed much. First, where do bugs come from? The column "Malpractice" means these folks are software terrorists. "CMM3" refers to the third level of the Capability Maturity Model, which is considered a disciplined software engineering process. Where do they get removed? Jones introduced the notion of "Defect Removal Efficiency", which is the percentage of the bugs removed during development and up to 90 days after initial delivery, out of the total universe of defects in the product, including those found in development. Here's his numbers: So the very best companies can expect 30 bugs in a 100 KLOC project! Alas, few are even close to that level. |
||||
| Failure of the Week | ||||
From Tom Van Sistine: Geiff Field wrote: On a game I've been playing (probably too much), there's a prize given when you earn a certain amount of "stars". Have you submitted a Failure of the Week? I'm getting a ton of these and yours was added to the queue. |
||||
| Jobs! | ||||
|
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intent of this newsletter. Please keep it to 100 words. There is no charge for a job ad. |
||||
| Joke For The Week | ||||
These jokes are archived here. Technology is dominated by those who manage what they do not understand. |
||||
| About The Embedded Muse | ||||
|
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. |