How much abstraction is too much? Phil Matthews ponders this:
|
Recently I had to work on some embedded software for a PIC24 that would reset another chip by pulsing an I/O pin low for 160usec.
The code I found had a function "reset_chip()", which created a message that was posted on a message bus to a task in a "reset object" that subscribed to the message. The message was dynamically allocated on the heap and linked into a message queue. The message contained a pointer to the message data which was also dynamically allocated on the heap. That "object" had 4-layers of hardware abstraction that ultimately pulled a GPIO pin low. Another timer object also subscribed to the same message and started a timeout with minimum resolution 10msec. The timer object was dynamically created in a linked list of timers. When the timer expired it generated a timer event object that posted a timeout message to a another task that subscribed to the timeout message. This caused the reset object, through 4 layers of hardware abstraction and logical pin mapping, to pull the pin high. The reset pin was low for anywhere between 10-20msec. Also it didn't always work, and sometimes went low and failed to go high (This is why I was working on it) .
I deleted 1500bytes of code and replaced it with 3 lines of C-code:
Set_gpio_pin(6, low);
Delay_ms(1);
Set_gpio_pin(6, hi);
When I pointed out how ridiculous the original code was, and asked why it was done that way I was told point blank, "It's object oriented". When I asked what problem is being solved by doing it this was the reply was "Everything is object oriented. It's the way software is done".
Admittedly this is an extreme example. However, over the years I have noticed embedded software becoming more complex for no apparent benefit. It looks structured, and follows some academic pattern. But is way too complicated, slow, memory hungry and full of bugs. I don't mean complicated systems. I'm meaning simple systems with unnecessarily complicated software. Why has this come about? Is it software guys becoming more and more distant from hardware?
When I started writing embedded software it had to be crammed into limited hardware. Simplicity was elegance. |
Many years ago a company, whose name everyone knows and whose products everyone uses, asked me to evaluate the status of a development effort. Their active product was powered by a single 16 bit, 16 MHz processor and all the code fit into 256k of memory. The code had evolved over decades; patch after patch added to the convoluted mess. Maintenance costs escalated yearly.
Engineering convinced management that a complete rewrite was needed. Not unreasonably they elected to go to a 200 MHz high-end 32 bitter (this is when that sort of processor was the bleeding edge in embedded work). Perhaps unreasonably, succumbing to the siren call of cool, the engineers elected to replace a traditional RTOS with Windows CE, an extensive graphics library, and many layers of middleware to insulate CE's API from the application, and to provide all of the resources needed to do, well, anything imaginable in the future.
Five years of development and $40 million in engineering crept slowly by. System memory ballooned from 256k to a meg, to two and more. When they called me the application now consumed 32 MB, yet included only half the functionality in the original, 256KB, 16 bit version. Button presses, which previously offered instantaneous response, now took seconds. The safety aspects of the system were in question.
The VP posed one question: What should they do?
After several days of evaluation I suggested they cancel the program and start over.
You'd think the idea of trashing $40m of effort would cause an uproar. Instead, the VP was so happy I thought she was going to kiss me.
Abstraction is a great and necessary part of our work. Now we have copious CPU cycles and cheap memory. But I continue to see products doomed or at least crippled by an excessive number of layers. Last year I was playing with a vendor library on an ARM part where toggling a GPIO should have taken tens of nanoseconds, but the convoluted library routines consumed tens of microseconds.
The mantra of OOP is encapsulation, inheritance and polymorphism. The first of these is the most important, and can be implemented in any language, OOPy or not. But too much of anything is a problem. A glass of wine enhances a night out; two bottles not so much.
Have you been burned by excessive abstraction? |
Last issue's article on naming conventions garnered a storm of reader replies.
Scott Romanowski wrote:
|
> Pack the maximum amount of information you can into a name.
I'd add "make certain names aren't similar" and "if you have two variables doing almost exactly the same thing, refactor to eliminate one". I once had the displeasure of using code that had two global variables, language_in_use and language_used, that were both indexes into tables, but they differed only in that one was 0-based and the other was 1-based. That is language_in_use had values of 0=NONE, 1=ENGLISH, 2=FRENCH, etc., in one, and language_used would be used only if language_in_use != NONE, and its values were 0=ENGLISH, 1=FRENCH, etc. But sometimes the developer would use table[language_in_use-1] in place of table[language_used]. The sad part is that I don't think it was an attempt at job security a la https://dilbert.com/strip/1994-06-10 because the developer was a Close Personal Friend Of The Founder. |
Martin Thompson contributed:
|
On naming conventions, a couple more thoughts:
- I'm sure we have all see TEMP – is that a temperature, or temporary?
- In cryptography it is common to have some lengths expressed in bits and some in bytes – my convention is that counts are always bytes. Counts of bits must have an _bits suffix.
- Nothing should ever be named Tx or Rx – it always gets confusing when viewing it from the other side of the interface. I always try to have pairs like "to_ecu/from_ecu" or "to_target/from_target"
|
Did the index variable "i" come from Fortran? Rob Aberg is not so sure:
|
When the i, k, ii topic came up, I was thinking to myself "ooh, ooh, ooh, I know":
TEM> because 60 years ago, when Fortran came out, variables starting
TEM> with the letters i through n were, by default, integers
Yes! ... all the while reminding me of the experience of seeing this in inherited code:
IMPLICIT DOUBLE PRECISION (A-Z)
But even then, little surprises were frequently rolling around in some spots:
INTEGER I, J, K, M, N
INTEGER II, JJ
and not in others. Sigh. Replacing with IMPLICIT NONE and building a data dictionary out of the error log was a systematic way of documenting of variables in inherited code. The first and best outcome of that was to learn the codebase ... and in the process, shake out a good number of bugs almost every time, with better documentation for future refactoring and porting.
That said, did Fortran invent the idea for i-n being integers? Since every mathematical textbook I own has formulae that use i, j, k, m, and n (+ capitals) for indices, viz:
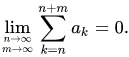 (from the Wikipedia article on "Convergent series") (from the Wikipedia article on "Convergent series")
It's likely Fortran cannot hold the root claim for that convention. It was an intermediary for sure, helping us get to where we are today.
Segue to the larger topic computing's history: there are vestiges of computer history hiding in plain sight all around us. How many can you spot? Some teasers to prime the pump:
- 8.3 file names
- the floppy disk icon for "save"
- the intersection of Computer Dr. and Technology Dr. in Westborough, MA**, nowadays without much of either computers or technology on those streets
** The recommended way to learn about this spot in history is to read "The Soul of A New Machine" by Tracy Kidder. This book is to computer hardware history as "The Cuckoo's Egg" is to network debugging history and "Hidden Figures" is to the acceptance of numerical methods over closed form mathematics in STEM. All involve protagonists with sleepless nights for months and years on a relentless quest -- essential reading for anyone whose family and friends glaze over when they talk about work. |
Rob Uiterlinden suggests using types to define units:
|
On naming conventions:
Append units to types, not variables.
Reason: DRY (Don't Repeat Yourself)!
For every unit you intend to use, define a type and state its unit in its comment. The type is defined once, and is used for every variable whose value is in that unit.
Naming convention: append '_t' to the type, similar to 'size_t'.
Example:
typedef float Velocity_t; /* Velocity [m/s] */
Velocity_t DesiredVelocity;
In this way, it is always clear what unit a variable has, and the unit is defined only once.
|
Then there's this from John Grant:
|
I can't remember where I first came across this rule, but the length of a name should be proportional to its scope and inversely proportional to the number of times it's used. So a loop index that's used half a dozen times in 4 lines of code can be a single letter, while a name that's used two or three times in different modules of a large program needs to be a fairly full description of what it does.
Regarding standard abbreviations, I use "rcv" rather than "rx" for receive, because "rx" can so easily be mistyped as "tx" and vice versa. |
But Bob Paddock prefers to include the units in the names:
|
I once went in to clean up a project that was designed by a committee of people spread all over the world. The unit was large moving equipment that if something went wrong, people might die. The unit was composed of several different CPU modules communicating on a property bus. Each module's software was written by a different group in a different part of the world.
The operator's requested speed was input in Feet Per Minute. The output to a Variable Frequency Drive was in tenths of Hertz. The tachometer feedback was in RPM, and to top it off all the internal calculations were done in Radians-Per-Second.
The first thing I did to get the project back on track was to adopt a standardized variable naming convention that included the units. For example the Operator Request became operator_request_fpm_u16. You then knew immediately you were dealing with Feet Per Minutes, and that it was a 16 bit unsigned variable. After the variable name cleanup many of the bugs became self documented, when you saw something like
"operator_request_fpm_u16 / vfd_hz_s32" in the code, you knew there was a problem that needed to be fixed... |
Martin Buchanan wrote:
|
I thought I was a naming expert, having written more than one coding standard and being quite conscious of naming, however I learned things from your brief article. Your Linnaean taxonomy suggestion is excellent.
Two other naming suggestions:
1. Names used extensively, dozens or hundreds of times in code, should be short rather than long. For example, if you have a main database schema named "publications" and you have ten thousand lines of SQL, you will be typing that schema name far too many times. A short name like "pub" would be better.
2. Don't be too fond of your company name, in case your company is renamed or acquired. If your company name "QuantumBlockchain" appears hundreds or thousands of places in code and in directory names or file names, such as quantum_blockchain/quantum_blockchain_config.yaml, then it will take significant work to change it. Ditto for product names. |
Pete Friedrichs and I agree about comments:
|
I haven't done much coding in recent years, (no present job requirement for that) though in years past, I did a LOT. This included assembler, Fortran, Pascal, various Basics, and various C's. It was always my practice to strive for a level of commentary and naming convention such that, if someone were to take my source files and delete all of the actual code, the remaining header blocks, comment lines, and variable references would be comprehensive enough to explain, in detail, what the code would have done.
Believe it or not, I've been criticized for that. But, disk space is cheap, my compiled code is no larger than the guy's code who documents nothing, and I can open my source five years after the fact and tell you exactly how it works. Real men DO eat quiche. |
Clyde Shappee takes naming seriously in HDL designs:
|
The part about naming rules brings up another point I would like to make in the name of code clarity. That is, constants, especially ones which will be used in decision making logic should be given in real world engineering units.
The number by which a decision is made comes from a transducer and that is conditioned and read by an A/D converter. The math should be encapsulated in the constant definition itself or somewhere else so that nobody has to go back and do it over when a change is made.
I don't know how this works in C or similar languages, but this was done in a Verilog HDL design I worked and we handed off maintainable code to our client. We spent hours getting the physical units correct as we could, but no doubt in the real world they would need to change. So a constant like read Turn_Around_Time_Maximum_seconds = 3.1E-3 for 3.1 milliseconds could be adjusted handily. Look, Ma! No math! |
Nat Ersoz references a fun article:
|
Naming is hard!
https://martinfowler.com/bliki/TwoHardThings.html
It is so funny. Well, naming is hard and worth the time to think about it.
Some things our group adheres to:
- Almost always, spell it out. You want the total, use the name, like
uint16_t total_incidents_encountered = 0u;
Especially when declaring members of a composite type. The more global the name, the more important clarity is. Some local variables with shortened names are fine.
- Avoid i,j,k alone as iterators. It is no deadly sin, but when you're searching for usage it is much easier to say iter_i or iter_j.
- Avoid the use of the word "manager". Think long and hard before using this word. In our group we are plagued with "helpers" - which, in most cases are adapter patterns. We have now tried to reduce our dependency on that word as well.
What is a manager? Is not every bit of embedded code part of a manager? i.e. are we typically not managing some device? So what is that object or module? How about a PowerUpSequencer, a SPI driver, a CommandTransactor? Use of pattern names helps: InterruptObserver and InterruptObservable are good names.
- When dealing with measurement units, always, always, always embed the units in the name:
uint32_t time_helper->get_tick_count_us();
// There is that helper thing again...
uint32_t lo_frequency_khz = 0u;
Units are microseconds. Units we always abbreviate, and use lower snake_case regardless. |
|
Miro Samek responded to comments in Muse 440:
|
I enjoyed "Testing For Unexpected Errors - Part 2" in TEM 440, but I'm really surprised that no contributor mentioned simple assertions. No takers? Really? Aren't assertions exactly for "testing for unexpected errors"?
I think that especially younger readers need to be reminded, ad nauseam if necessary, about benefits of assertions. And this includes leaving assertions enabled in production code, especially in safety-critical applications. There is a reason why "NASA's Ten Commandments Of Programming" have Rule No. 5 – Assertion Density:
https://www.profocustechnology.com/software-development/nasas-ten-commandments-programming/ |
That article Miro cites is very important. Please read it.
Russell Pinchen sent this:
|
Just wanted to add a few comments to the conversation on testing for "unexpected errors". I would argue you can't test for unexpected errors as by definition they are unknown. You could however test for known ones, and declare anything outside that scope as unexpected.
With regard to critical systems a good approach is starting with the assumption that there are likely to be unexpected states a system can transition to, and start with a design principle of "design for failure". I would also add the system must always fail into a safe state. I concur with statements made in issue 440 the definition of a safe state depends on the system under consideration, and is governed by the real world that system is connected to.
Given the above, if known states are defined and specified (be they error or required ones) any thing else is an unexpected one. This may be a simplistic view, but I like it simple. The trick, I guess, is to detect when something unexpected has occurred, assuming the obvious ones are detailed out (e.g. lost comms to a sensor).
In some of the safety critical environments I have come across supervisory systems can be effective for this purpose. For example monitoring a simple safety circuit, winding its way through a series of lift doors. The supervisory system not only monitors the safety circuit integrity, but also the sequencing of the circuit within the context of the wider door operation. This is a good indicator something unexpected is up (could be someone fiddling with the safety circuit)
I have also been following with interest investigation No. HWY18MH010 by the National Transportation Safety Board. The incident under investigation involved an automated self-driving car which collided with, and killed, a pedestrian. There are a number of factors contributing to the accident but the ones of interest for me are,
- It appears, the Automated driving system failed to classify the pedestrian until it was too late (unknown state),
- The OEM collision detection and avoidance system was disabled while in auto-driving mode (supervisory system).
- Assumption that operator will provide mitigating actions.
The report can be found here. https://www.ntsb.gov/investigations/AccidentReports/Reports/HAR1903.pdf |
|