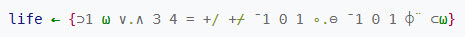|
||||
You may redistribute this newsletter for non-commercial purposes. For commercial use contact jack@ganssle.com. To subscribe or unsubscribe go here or drop Jack an email. |
||||
| Contents | ||||
| Editor's Notes | ||||
Tip for sending me email: My email filters are super aggressive and I no longer look at the spam mailbox. If you include the phrase "embedded muse" in the subject line your email will wend its weighty way to me. According to EETimes the chip shortage could extend into 2023. It seems the worst problems are in bleeding edge parts. But one quote caught my attention: "The auto industry is thinking on fractions of a day of inventory." A hard-hitting piece in Electronic Design explores the benefits of SMT technology, and explains what it is. Really? I thought the article's date might be 1990, but nope, it's 2021. AD. I get a lot of email complaining about the declining quality of the trade press and this piece is a shining example. Of course, there are counterexamples, like Philip Johnson's excellent and recent A General Overview of What Happens Before main(). |
||||
| Quotes and Thoughts | ||||
Shore's First Law of Programming: "Never test for an error condition which you can't handle." - Chris Shore |
||||
| Tools and Tips | ||||
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past. Sergio Caprile sent a good debugging lesson in the Strange Case of the Board That Would Not Power Down. Hunter Scott has written an excellent book about designing electronic systems. It covers that which is missing in college: how to design systems one can actually build (like, tradeoffs between capacitor types), and that will work. The PDF is free, though you do have to enter your email address. A printed version is available for $39. Highly recommended. Here's a decent article comparing PCB design packages. Replying to the RAM testing comments in Muse 424 Luca Toso wrote:
|
||||
| Freebies and Discounts | ||||
Kaiwan N Billimoria has a new book out named Linux Kernel Programming, and it's a heck of a volume. At 741 pages it is very comprehensive. The book is very well-written and Kaiwan makes working on the kernel crystal clear, starting with basic concepts and giving detailed examples. If you've never built the kernel he goes through the process step by step. His follow-on book Linux Kernel Programming Part 2 - Char Device Drivers and Kernel Synchronization is about creating user-kernel interfaces, work with peripheral I/O, and handle hardware interrupts. Kaiwan kindly sent both books for this month's giveaway. Enter via this link. |
||||
| A Debugging Tip | ||||
Todd Mizenko sent this: I wanted to pass on a debugging technique I've used a couple of times in recent years. For the record I cannot claim this as my own and my apologies in advance if you have covered this technique before. It was something practiced by a team I was on a few years ago and I quickly came to see it's value in embedded systems as well as multi-threaded/multi-core server applications. I hope you find it interesting/useful. As you know, crashes on multi-threaded/multi-core embedded systems and servers can sometimes be difficult to debug. When a core file doesn't provide an obvious answer standard troubleshooting is often done either with a debugger (e.g. gdb, Trace32) or logging ("printf-style debugging"). While using the former can be useful for gaining insight into a crash, it's often difficult or impossible to deal with other cores/threads that are still running while trying to debug, which can in turn lead to side-effect errors such as buffer overflows, timeouts, and crashes in other threads. For the latter, adding targeted logging can affect system run-time performance and "push" the problem elsewhere or make it disappear altogether. In addition, at the highest logging levels pertinent information may end up being dropped. Last, logging is often buffered and may not be flushed when a crash occurs. So what else can be done when both of these debugging methods are inappropriate? Another arrow in the quiver is what I have termed "circular buffer-based debugging". Basically the technique is to create a data structure that encompasses or describes the problem you are trying to debug, packing that structure into an appropriately-sized (meaning small!) circular buffer, instantiating the buffer somewhere readily available for post-crash processing, and updating it at appropriate times in the code. After the crash happens you open up the core file and examine the contents of the buffers. Depending on what you are trying to do you may need multiple buffers going at once, for example for both a message producer and consumer. The advantages to this technique are:
The cost is mainly the memory required to instantiate the buffer(s) and obviously the buffer and structure sizes chosen should be the minimum required to elicit useful information. Example: I was recently trying to debug a crash on Linux where a thread was crashing on what appeared to be some form of a double-free of an underlying message buffer. Both of the usual techniques didn't help: I didn't have easy access to the running system, the problem was likely not being caused by the receiver/crashed thread, and logs at the point of crash were not getting flushed. So I added a data structure showing relevant details about the message contents (e.g. message pointer, buffer pointer, size, length, headroom, tailroom, etc.), instantiated a buffer for one message sender thread and two message receiver threads of interest and updated the entries in the buffer as appropriate when sending and receiving. (The sender and first receiver were related by the same message, the second receiver also used message buffers from the same pool and contained updated code.) Once I had the core file, it was easy to use gdb to figure out exactly what was going on. On the crashed side (the first message receiver) at the last index the buffer data pointer, size and length were incorrect. On the transmit thread side at the same index everything looked ok. On the other receiver thread I observed that at the last index it was also operating on the same message buffer as the other two. AHA! A detailed look at the code revealed the error that I missed previously, which was a twist on a double-free: the buffer in question was being freed in the second receive thread, allocated in the sender thread, mistakenly freed again in the second receive thread (which was valid to do since the buffer was now allocated), and then accessed (now invalid) by the first receive thread. Removing the extra free in the second receive thread solved the problem. |
||||
| On Maintainability | ||||
Over the years I've worked with a lot of academics. Most are pretty tuned in tot he realities of building systems that work. Some, well, less so. Several have told me we need to use the highest level of abstraction that we can; that fewer lines of code means better and more maintainable code. Really? Consider APL, a language so compact that it used a huge array of special symbols. In the days before GUIs a special keyboard and display were needed to work with it. Here's a complete APL program that plays the game of life:
APL was popular for a time, but we soon learned it is a write-only language. An hour after making a program work it's pretty much incomprehensible. Maintainability doesn't spring to life from some selected language. I've read assembly code that was so beautiful it was like an exquisite poem, and C++ that made me want to vomit. It comes from how we write the code. How we select names, structure the statements and craft the algorithms. Careful commenting, and avoiding arcane syntax are all part of this craftsmanship. Reducing the number of lines of code does not inherently lead to comprehensible programs. The language is never a panacea. Coding discipline driven by pride in our work is the tool that leads to code that people are happy to maintain. I think the three meta-factors in this are well-written code, well-documented code, and the use of a living language. Consider the last of those three. You could write the greatest novel of all time in Latin. No one (to a first approximation) will read it. Yet Latin is a fantastic lingo with regular conjugations. English, by comparison, is a mess. I was once asked to give some advice about a 5 million LOC program commented in Czech. There are only 13m Czech speakers in the world. The company was ready for major expansion and wanted to set up engineering sites in a number of countries. They had coded themselves into a black hole. There's another excellent language that only a fool would use today: HAL/S. It was only ever used on a single product: the Space Shuttle. New hires were required to spend 6-12 months learning it, during which time they were unproductive. Now, that is taxpayer money, and there's plenty of that. But in the real world HAL/S is a singularly poor choice for building products. HAL/S, APL, and too many other languages are all the Latin of our community. It's possible to build products with these. It's all but impossible to maintain them. |
||||
| Failure of the Week | ||||
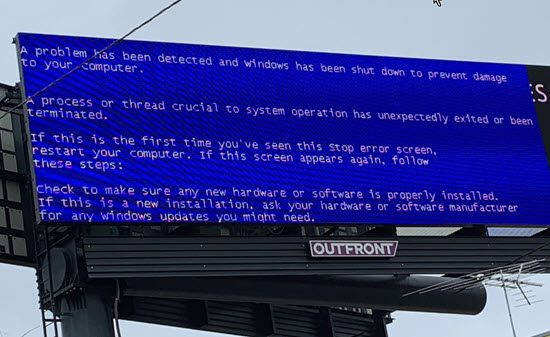
Steven Olson sent this, a sign seen on Highway 101:
Have you submitted a Failure of the Week? I'm getting a ton of these and yours was added to the queue. |
||||
| Jobs! | ||||
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intent of this newsletter. Please keep it to 100 words. There is no charge for a job ad. |
||||
| Joke For The Week | ||||
These jokes are archived here. "There are three things a man must do "APL is a mistake, carried through to perfection. |
||||
| About The Embedded Muse | ||||
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. can take now to improve firmware quality and decrease development time. |