|
You may redistribute this newsletter for noncommercial purposes. For commercial use contact jack@ganssle.com. |
| Contents |
|
| Editor's Notes |
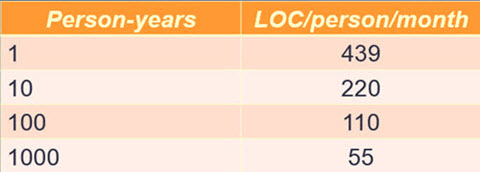
IBM data shows that as projects grow in size, individual programmer productivity goes down. By a lot. This is the worst possible outcome; big projects have more code done less efficiently. Fortunately there are ways to cheat this discouraging fact, which is part of what my one-day Better Firmware Faster seminar is about: giving your team the tools they need to operate at a measurably world-class level, producing code with far fewer bugs in less time. It's fast-paced, fun, and uniquely covers the issues faced by embedded developers. Information here shows how your team can benefit by having this seminar presented at your facility.
Better Firmware Faster in Australia and New Zealand: I've done public versions of this class in Europe and India a number of times. Now, for the first time, I'm bringing it to Sydney on November 9 and Auckland on November 16. There's more information here. Seating is limited so sign up early.
James Newman is building a custom computer. Out of discrete transistors. 14,000 of them! More info here. |
| Quotes and Thoughts |
"I am a design chauvinist. I believe that good design is magical and not to be lightly tinkered with. The difference between a great design and a lousy one is in the meshing of the thousand details that either fit or don't, and the spirit of the passionate intellect that has tied them together, or tried. That's why programming - or buying software - on the basis of "lists of features" is a doomed and misguided effort. The features can be thrown together, as in a garbage can, or carefully laid together and interwoven in elegant unification, as in APL, or the Forth language, or the game of chess." - Ted Nelson
|
| Tools and Tips |
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past.
EEPROM, like flash, has a limited number of erase/write cycles. Mostly we tend to ignore this (though in flash it's common to do wear leveling). Atmel and Microchip have worthwhile application notes about extending the number of cycles, potentially a lot, using smarter code that stores parameters in multiple places, like using a circular buffer. Atmel's is here and Microchip's here. Well worth reading.
Way back in 2005, in Muse 112 I listed magazines and other resources that we embedded people should read. That list is long overdue for an update, which I'll do one of these days. But one I've been following rather avidly is Elektor.com. Rather in the flavor of Adafruit and Sparkfun Elektor has all sorts of projects and kits for sale. Somewhat uniquely, though, they have a free newsletter (sign up at http://www.elektor.com/newsletter) and their own in-house lab which is the source of a lot of the content of the site and of the newsletter. There's also a very worthwhile paid magazine available in digital or print editions; each issue has a rather amazing number of how-to articles covering both hardware and firmware aspects of building systems. Highly recommended for those who like hands-on projects.
Two things captured my interest this week. The first is that, for a limited time, subscribers to the newsletter will get three e-books (LEDs, Embedded Linux, and Microcontrollers and Tools) for free. The second is they're selling the Red Pitaya open-source scope/RF generator for half price. The Red Pitaya is generating a lot of buzz. An article from Elektor's magazine gives a number of experiments one can do with this device.
Another great resource is Steve Leibson's blog. It's very Xilinix focused, but I find it's a good way to keep up with what's going on in the higher-end FPGA space. Steve adds entries several times a day; I find it convenient to read an entire week's worth each Monday.
|
| Freebies and Discounts |
Congratulations to Kevin Buckner who won the Gabotronics oscilloscope!
I bought a $50 zero to 10 MHz signal generator from eBay. It's a new unit which was shipped from China; these things are for sale all the time on that site. I'll do a review of the unit, but it will be this month's giveaway, which will close at the end of August, 2015. Go here to enter. It's just a matter of filling out your email address. As always, that will be used only for the giveaway, and nothing else.

|
| In-the-Field Firmware Updates |
In the last issue I asked how people go about doing in-the-field firmware updates. Several readers had replies.
Daniel Morris of eCosCentric (the people who support the eCos RTOS) wrote:
|
I noticed your question about how to manage firmware updates for devices in field in this week's newsletter. We have two solutions available with eCosPro!
Over a decade ago we developed our Robust Boot Loader. It has been used with applications as diverse as overnight updates on high-speed trains in France, refrigerated lorries in Scandinavia and building controllers in North America (and then around the world). In essence we extended RedBoot (our bootstrap code), removing the single points of failure and provided a mechanism to work similar to mirroring on an enterprise system. A fresh image is loaded into a redundant area, validated, started, re-validated and then once we're happy the "old" image's space becomes the reservoir for assembling a new update. Image integrity is critical, as was testing to ensure that the system was resilient if (for
example) the power failed/was disconnected during the reprogramming stage. Versioning is managed to make sure that previous updates aren't written over a newer installed image, unless the application developer really, really, really wants to!
In the case of the refrigerated lorries, we worked with a tiny 16KiB buffer to collate inbound images (2-4MiB) over a very low-speed GSM link, over many days. For the building controllers we applied the same versioning to data as well as code, so different operating parameters/datasets could be used for the changing environmental conditions to reflect how the valve responses should change from summer through autumn (fall) etc.
We also provide a mechanism to hang a physical switch, dongle or even magic sequence of bytes on a serial link, for a technician to initiate a service update, as well as the software methods from an application.
You can find further details in our online documentation at the following URL:
More recently we've developed our eCosPro-BootUp framework, which is better suited to very small scale systems, such as SoC parts and Cortex-M3/4/7 class parts that have a finite amount of on-device flash. A design trade-off with the Robust Boot Loader is needing double the image space.
We've also seen devices emerge that need us to work in concert with a manufacturer's multi-stage and/or secure bootstrap routines, such as Cortex-A class microcontrollers. We also have clients that deploy groups of update files, which have to be written to sub-systems attached to the micro, such as DSP firmware, FPGA bitfiles or raw datasets. We include decompression and validation routines and images may be on external media.
Universally, eCosPro-BootUp is designed as the first code to run in the system and is intended to be left in-situ during any updates. It gets out of the way once the initial system is loaded, so doesn't add an overhead to a running system.
Again, the core documentation for the BootUp framework is available on our website, although some implementation issues are specific to our clients' proprietary hardware and/or restricted by NDA for some of the Secure Boot steps. The direct link to the public elements is:
http://www.ecoscentric.com/ecospro/doc/html/ref/bootup.html
Talking with potential customers over the years, one thing that does strike is me is that sometimes these design choices are made after the development phase. Some physical cases, such as being a few hundred feet up/down a lift shaft with limited access to a reset button, do drive these decisions further towards the front of the plan. In some cases, such as Set Top Box design, the immaturity of the tech means that an update mechanism has to be designed in from the outset. |
Frank Voorburg wrote that OpenBLT is one mechanism:
|
The OpenBLT firmware update sequence is as follows:
(1) The flash memory, which is to be rewritten, is erased.
(2) The new firmware is communicated to the bootloader and programmed into flash memory in small chunks of data. Typically 7 - 64 bytes, depending on the used communication interface (CAN, UART, USB etc).
(3) As the last programming step, a 16-bit checksum value is programmed into flash memory at a fixed location. This is not a checksum of the entire firmware, but typically just a checksum of the vector table. It serves as a marker to determine if the firmware was completely programmed or not.
(4) Once done, the new software program is started after performing a checksum verification.
After a microcontroller reset, the bootloader is always first active. It will only start the user's firmware if it is present, by performing the checksum verification. Thanks to this checksum mechanism, problems during the firmware update procedure (communication lost/power failure) do not cause any problems. The worst case scenario is that the bootloader remains active, which allows the firmware update to be restarted.
Thanks to the feature that the firmware data is communicated is small chunks of data, the OpenBLT bootloader can also run on low-end microcontrollers with limited RAM.
Additional details regarding the design of the bootloader can be found
at: http://feaser.com/openblt/doku.php?id=manual:design.
|
Chris Maier is also using OpenBLT and writes:
|
We are using OpenBLT in our devices for firmware updates and never had a problem with it. It supports SD card, UART, CAN, TCP/IP, and USB. |
Dan Swiger had a number of thoughts about this:
|
Firmware update methods depend upon the type of embedded platform.
Bare-Metal: If you are in control of everything, say with an embedded RTOS and a little bit of boot-strap code (crt0.asm, perhaps), then my method is to have three code sets (with one of them duplicated):
Boot-Check -- This is a very small bit of code that uses the boot-strap to get the processor alive, then check the rest of the FLASH memory to see who is available to run. This thing must be absolutely bullet-proof when you deliver the product, as it cannot be updated! This code first tries to run the Run-Time code, then the Enhanced Boot-Load, and will finally fall back to the Factory Boot-Load, if nothing else works. You can also put in physical switches or special commands to force a particular set of code to run. Think of it as a "get out of jail free" card. If you totally FUBAR the Run-Time code, you can flip a switch to make the Boot-Load code run, so that you can load a new, better Run-Time code (or revert to an older, less broken one). In addition to the physical switches, the Boot-Check can use a combination of checksum calculation, version numbers, or "good markers" to know what code should be run.
Factory Boot-Load -- This is a slightly larger bit of code that interfaces to the outside world (Ethernet/USB/RS-232/etc.) to accept firmware updates, and little else. To create this code-set, usually strip out most of your Run-Time code down to just the bare external interface.
Enhanced Boot-Load -- When a product ships, this code segment is empty, allowing for future upgrades of the Factory Boot-Load, if you have some bug in it.
Run-Time -- This is the main body of code that makes the product do, whatever the product is supposed to do. It should include some command across the user interface to force it to reboot into the Boot-Load for firmware updates.
As for the updates themselves, you classically don't have enough space to hold two complete code-sets of your Run-Time code, so choose a download method that is chunky, like S-Records. When you go to start an update, erase the entire Run-Time FLASH allocation and then start downloading and burning one S-Record at a time. Checksum each record both at the incoming interface, and as it is burned into the FLASH. Flag an error back to the user on any checksum failure. Once the entire code is downloaded, checksum the entire Run-Time FLASH allocation and compare to the known checksum (obviously you'll have to have your boot-loader calculate it for you and report it to you as a developer). Assuming the checksum all matches, indicate that this code is "good to run" for the next time the Boot-Check is looking for code.
Linux-Distro: If you are developing an application on top of Embedded Linux, say with a U-Boot/X-Load boot-strap, then I have always opted for a "monolithic upgrade" path. I usually don't allow the boot-strap code to be updated in a fielded unit, but upgrade the Kernel, RootFS, and my applications as a single entity. Give the user one "upgrade.tar.gz" containing a manifest file (letting the upgrade engine know what is being upgraded, with MD5 checksums) and the files to upgrade. Then FTP/SCP the file onto the unit and issue a single command to start the upgrade.
The upgrade itself is either a single, or perhaps multiple staged shell scripts to erase FLASH, program FLASH and possibly reboot. For instance, if you are running from an NAND-based RootFS, you cannot upgrade the RootFS from which you are running, so you need to have "factory" and "enhanced" versions of the Kernel and RootFS so that you can "swap" between them during the upgrade process. During the upgrade, the upgrade.tar.gz contents will be copied to a non-volatile area, the "enhanced" kernel will be deleted, then system will be rebooted into the "factory" Kernel+RootFS. The "factory" code will see the upgrade files present and know that it has to erase and program the "enhanced" Kernel+RootFS images. After upgrading the images, the "factory" code removes the upgrade files and reboots back into the upgraded Kernel+RootFS.
The logic to switch between "factory" and "enhanced" can be supported by a series of U-Boot commands that first tries to load the "enhanced" Kernel, falling back to the "factory" when the "enhanced" fails.
There's a lot more detail that goes into this, but hopefully it gives you a rough idea of one way to accomplish firmware upgrades.
|
|
| Second Sources |
The very first board I designed that used FPGAs, back in the early 90s, had a huge hunk of firmware. We popped out a prototype board pretty quickly, which gave the software people a test platform. The code was complex; development dragged on for over a year before the system was customer-ready.
By then we couldn't buy FPGAs. The vendor had obsoleted them in favor of a newer, bigger, faster, more feature-rich part.
Disgusted, we delayed shipping for three months while re-engineering the board with new parts from a different vendor. Those extra months of engineering and lost revenue trashed the year's profit and loss statement.
Ironically, the main impetus for designing that product was that its older version used a peculiar kind of memory device that had itself gone out of production. That vendor had notified us well in advance so we could order a sufficient quantity to tide us over for a time.
In the distant past engineers expected parts to have second sources, alternative vendors who would continue to produce their products even if the prime got out of the business. Identical microprocessors were available from many companies. Logic devices were all elements of accepted families of products. Everyone made CMOS logic. Everyone made TTL components.
Today that's much less the case. Vendors tout their own "solutions" which, while generally wonderful bits of technology are hopelessly proprietary. The customer succeeds at the whim of the vendor; if they discontinue a part, you're plain outa luck with no attractive options.
In my travels I often hear such tales of woe. So many products use components with such short lifecycles that there's a re-engineering required before the first units even make it out the door.
It's easy to understand where the problems come from. In the olden days there weren't nearly so many variants of ICs and other components. How many distinct CPUs existed in, say, 1980? Consider the Cortex M or PIC today: Each of these comes in hundreds of flavors, each tuned to a narrow market segment. Second sourcing isn't financially viable. (To be fair, many developers tell me they use PIC microcontrollers because Microchip seems to keep their parts available forever).
Yet customers do need stable sources of supply. Some embedded systems stay in production for achingly long periods of time. So a few companies fill their inventories with decades' worth of parts, to the shrill howls from accounting and senior management. Though the parts may be critical to long-term success, IRS rules require depreciating them. Inventory's value -- and thus the company's, since inventory is on the balance sheet -- declines. That's no way to satisfy the stockholder.
The obsolescence of parts could be considered a job security program for EEs, but none of us care to work on old equipment, and it's certainly not a money-maker for the company.
In some industries vendors tell me they have to keep spares available for 30 years. Can you imagine? Three decades ago, in 1985, Intel's hot part was the 286! Freescale was Motorola. The first FPGA came out, and it only had two three-input lookup tables. Microchip's formation was four years away. Most components were thru-hole mounted.
What's your take? Have you had problems with parts going off the market? What action do you take?
|
| Jobs! |
Let me know if you’re hiring embedded
engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intents of this newsletter.
Please keep it to 100 words. There is no charge for a job ad. |
| Joke For The Week |
Note: These jokes are archived at www.ganssle.com/jokes.htm.
Martin Grill sent this screenshot from howstuffworks.com. Check out the circled page numbers:
|
| Advertise With Us |
Advertise in The Embedded Muse! Over 23,000 embedded developers get this twice-monthly publication. . |
| About The Embedded Muse |
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and
contributions to me at jack@ganssle.com.
The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get
better products to market faster.
|



