|
|
||||
You may redistribute this newsletter for noncommercial purposes. For commercial use contact jack@ganssle.com. |
||||
| Contents | ||||
| Editor's Notes | ||||
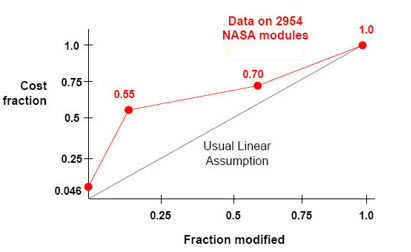
Many of us think there's some sort of more or less inverse linear relationship between the amount of software reused and the cost to create firmware. Turns out, that isn't true. NASA has shown that once you start fiddling with about a quarter or less of the code reuse's benefits start to melt away.That's not to knock reuse; I feel that it's probably our only hope of salvation as programs soar in size. But it does say a lot about how we need to go about reuse to get the benefits it promises. This, and a whole lot more, is part of my Better Firmware Faster seminar. It gives your team the tools they need to operate at a measurably world-class level, producing code with far fewer bugs in less time. It's fast-paced, fun, and uniquely covers the issues faced by embedded developers. Learn how your team can benefit by having this seminar presented at your facility. India update: I will be doing a three day version of this class, open to the public, in Bangalore, India July 15-17. For more details Please contact Santosh Iyer on +91 9819115569 or mail santosh@goldmancommunications.com with the following details: Your Name: |
||||
| Quotes and Thoughts | ||||
When you turn an ordinary page of code into just a handful of instructions for speed, expand the comments to keep the number of source lines constant. |
||||
| Tools and Tips | ||||
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past. If you're using more than one channel on an oscilloscope, how to you figure out which probe goes to which channel? Sure, probes always come with circular plastic loops of different colors that slip on over the probe ends, but they tend to fall off and get lost. I've taken to using colored ty-wraps. A bag of differently-colored cable ties is just a few bucks at Home Depot, and they last forever:
Can you see what's wrong with the picture? I should have matched the probe colors to the colors the scope uses to identify channels! |
Logic Analyzer Giveaway | |||
We ran a contest last month for a giveaway of a GW Instek GDS-1052-U bench scope. The lucky winner was Matt Bennett from Austin, TX. This month I'll give one of Saleae's nifty Logic Pro 8 logic analyzers to an Embedded Muse subscriber. The giveaway will close at the end of June, 2015. Go here to enter. It's just a matter of filling out your email address. As always, that will be used only for the giveaway, and nothing else. |
||||
| More on Multicore | ||||
Paul Bennett wrote in response to the comments about multicore in the last issue:
|
||||
| A Twist on Multicore | ||||
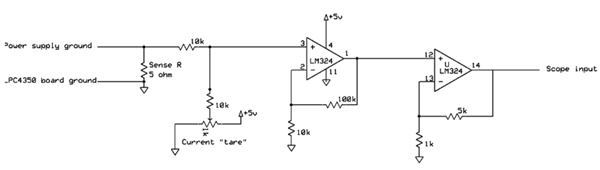
"Multicore" means, to many people, using a couple of big power-hungry x86 devices on a single piece of silicon. But in the embedded world we often have different concerns. One of those is trading off power consumption versus performance. Today a several vendors make MCUs that use a mix of cores. For instance, a single chip might contain both an ARM Cortex M4 and M0. The M4 runs fast and hot, the M0 offers much less performance while sipping coulombs frugally. NXP's LPC4350 is an example. I thought it might be fun and instructive to run the same code on each of the cores and see how power and performance differed. NXP was kind enough to supply a development board from Hitex. It's challenging to measure the difference in power used by the cores as there's no way to isolate power lines going to the LPC4350. The board consumes about 0.25 amp at five volts, but most of that goes to the memories and peripherals. To isolate the LPC4350's changing power needs I put a resistor in the ground lead to the board, and built the following circuit. The pot nulls out the nominal 0.25 amp draw, and op amps multiply any difference from nominal by 50. The output is monitored on an oscilloscope.
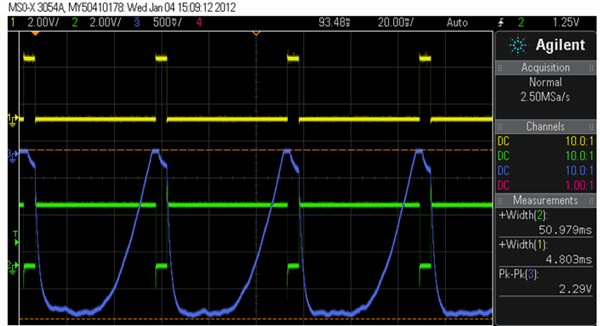
The cores run a series of tests, each designed to examine one aspect of performance. Each runs a test alternately, going to sleep when done. Thus, after initialization only one core is active at a time. When running a test the core sets a unique GPIO bit which is monitored on the scope to see which core is alive, and how long the test takes to run. One of those GPIO bits is assigned, by the board's design, to an LED. I removed that so its consumption would not affect the results. All of the tests use a compiler optimization level of --O3 (the highest). The tests are nearly identical on each processor, with exceptions noted later. Keil tools were used. The following picture is an example result. The top, yellow, trace is the M4's GPIO bit, which is high when that processor is running. The middle, green, trace is the bit associated with the M0. Note how much faster the M4 runs. The lower, blue, trace is the amplified difference in consumed power. I attribute the odd waveform to distributed capacitance on the board. It's clear that the results are less quantitative than one might wish. But it's also clear the M4, with all of its high-performance features, sucks more milliamps than the M0. So the current numbers I'll quote are indicative rather than precise, sort of like an impressionistic painting.
In the first test the processors took 300 integer square roots, using an algorithm from Math Toolkit for Real-Time Programming by Jack Crenshaw. Being integer, this algorithm is designed to examine the cores' behavior running generic C code. The M4 completed the roots in 1.842 ms, 21 times faster to the M0's 38.626 ms, but the M0 used only a quarter of the current. The next test ran the same algorithm using floating point. The M4 shined again, showing off its FPU, coming in 12 times faster than the M0 but with twice the power-supply load. There's considerable non-FPU activity in that code; software that uses floating point more aggressively will see even better numbers. The next experiment also took 300 floating point square roots. The M4 has a hardware square root instruction which I invoked by the __sqrtf() intrinsic instead of the M0's conventional C function sqrt(). The M4 just screamed with 174 times the performance of the M0. It was so fast the power measurements were completely swamped by the board's capacitance. One of the Cortex-M4's important features is its SIMD (single instruction, multiple data) instructions. To give them a whirl I implemented an FIR algorithm that made use of the SMLAD SIMD instruction. Since the M0 doesn't have this I used the macro from the CMSIS that requires several lines of C. Not surprisingly, the M4 blew the M0 out of the water, completing 20 executions of the filter in 5.15 ms, 10 times faster than the M0 for 9 times as many milliamps. But I was surprised the results weren't even better, considering how much the M0 has to do to emulate the M4's single-cycle SMLAD. So I modified the program with a SIMD_ON #define. If TRUE, the code ran as described. If FALSE, the SMLADs were removed and replaced by simple assignment statements. The result: the M4 still ran in 5.15 ms There was no difference, indicating that essentially all of the time was consumed in other parts of the FIR code. In other words, code making heavier use of the SIMD instructions will run vastly faster. One note: generally the M4 consumed less energy than the M0, despite the higher current consumption, since the M4 ran so much faster than the M0. It was asleep most of the time. Remember, energy is watts (I2R) integrated over time. In many systems a CPU has to be awake to take care of routine housekeeping functions. It makes little sense to use the M4 for these operations when the M0 can do them with a smaller power budget, and even handle some of the more complex tasks at the same time. Though the LPC43xx family is positioned for applications needing a fast processor with extensions for DSP-like applications, coupled with a smaller CPU for taking care of routine control needs, it's also a natural for deeply embedded situations where a dynamic tradeoff between speed and power makes sense. |
||||
| Jobs! | ||||
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intents of this newsletter. Please keep it to 100 words. There is no charge for a job ad. |
||||
| Joke For The Week | ||||
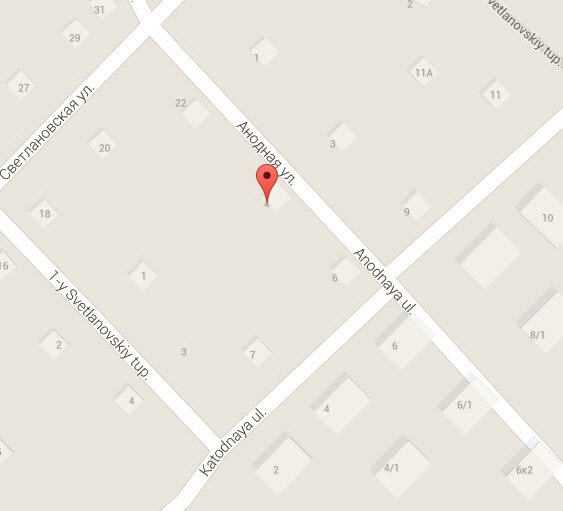
Note: These jokes are archived at www.ganssle.com/jokes.htm. Bruno Vermeersch has taken the roads-named-zero theme further: Didn’t think of it before but this week’s joke makes me think of the ring road around Brussels which is called R0: http://en.wikipedia.org/wiki/Brussels_Ring (with a few pictures). This article is in Dutch only but it gives a list of the Belgian ring roads, starting from 0: And Vladimir Pervokvaker wrote: Speaking of funny geographical names, there are two streets in my town (Novosibirsk), called "Anode street" and "Cathode street", and they are actually crossing each other:
|
||||
| Advertise With Us | ||||
Advertise in The Embedded Muse! Over 23,000 embedded developers get this twice-monthly publication. . |
||||
| About The Embedded Muse | ||||
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. |