Over 400 companies and more than 7000 engineers have benefited from my Better Firmware Faster seminar held on-site, at their companies. Want to crank up your productivity and decrease shipped bugs? Spend a day with me learning how to debug your development processes.
Attendees have blogged about the seminar, for example, here, here and here.
I'm presenting a public version of the Better Firmware Faster seminar in Denmark, Sweden and Finland:
- Aarhus: May 10, 2019
- Copenhagen: May 14, 2019
- Stockholm: May 16, 2019
- Helsinki: May 17, 2019
There's more information here.
I'll also be speaking at the Electronics of Tomorrow conference in Herning May 8-9.
Jack's latest blog: Will Quantum Computing Ever Be Practical?
|
In the last Muse I wrote about software warranties. A lot of the responses more or less mirrored what Scott Winder wrote:
|
Some quick thoughts on the complications of adding warranties to software.
- Manufacturers' warranties are based on the premise that most or all warranty claims will be the result of quality control issues, and the risk can be (and is) calculated. The exception to this is when there are design issues, and the exposure then is costly and massive (think vehicle recalls). That cost is one of the primary drivers behind vehicle OTA (over-the-air) software/firmware updates.
- Put another way, an issue found in a single software installation has the potential to be an issue for the entire installed base. Any legal exposure can quickly become massive. Limiting warranty claims to situations that include financial or physical harm could mitigate this to some extent, but even then, the loss of productivity due to a software/firmware bug experienced by (for example) 25,000 company employees could turn into a substantial sum in court.
- Simplistically viewed, software comprises only half of the ultimate operating environment. Most software is designed to be run on a variety of different hardware configurations, and very few software houses have the resources to test their product in all of the environments in which it will eventually run, creating gaping test holes. Those that do test exhaustively also charge significant fees to cover those costs.
- Even in a strictly-controlled environment (think Apple hardware and OS), issues are bound to arise because end-user usage patterns for any complex software are impossible to thoroughly predict. Significantly increasing beta testing could help here, but would delay the release of new features and thus cede a competitive advantage. Beta is the new Alpha, and Release is the new Beta.
Ultimately the only way to ensure that most or all software is warrantied is to legislate it, which would even the playing field in the affected country but heavily saddle its companies in the global market. Some companies require warranties and/or indemnification from their software vendors, but this tends to happen in bespoke (or semi-bespoke) safety-critical applications and comes at a high price. Today's society is fixated on Faster and Cheaper - Better is for the shrinking crowd with time and money to spare. |
A reader whom I know personally wishes to remain anonymous as his company's business is providing software to the embedded community. He's concerned about warranties that cover patent infringment:
|
Most Terms and Conditions statements insist that companies must "defend and hold harmless" large corporations against IP infringement. Mostly that's about patent infringement. Companies selling software must swallow these terms.
Yet large corporations selling software have license agreements that specifically exclude IP infringement, or at least reserve the right to provide a workaround for the infringement.
I would be very interested to know how large corporations really handle these situations. For instance, they order Microsoft Windows which has license terms that clearly contradict their standard PO terms. My guess is that a huge amount of this inconsistency is simply ignored. Which begs the question - what is the point?
But we as software vendors must treat these things seriously.
These clauses defy reality in many ways:
- The US patent office database has over 8 million registered patents, and there are many more patent offices around the world that contain more patents.
- There is no way of even listing all the potential algorithms used in a piece of software. It is not even practical to define all the algorithms used in a piece of software because there is no language for this.
- Many patents contain the catchall phrasing of the style "although this invention applies to this technology it may be used in other different technologies", meaning you really need to read and understand every patent to have any confidence that one of your algorithms has not been patented by someone in some other form.
- The lawyers who argue these license terms rarely have any real understanding of software and algorithms.
- Asking companies to turn up in any court in the world to defend a piece of software that has cost maybe a few thousand makes no economic sense.
- The cost of an IP defense can be staggering.
The bottom line is that there is no way for a vendor to know if there is a patent covering some algorithm in a piece of software. The customers that impose these terms on software vendors are unlikely to achieve anything that could give them real protection, except maybe the Pyrrhic satisfaction that they could bankrupt a supplier.
An agreement that limits the damages to the cost of the product seems more equitable and reasonable, but is practically useless to the buyer.
Trying to ensure against this is also very problematic. We have made attempts to get such insurance. Even when you manage to get someone who will cover you for accidental patent infringement, they will exclude the most litigious organizations, which kind of defeats the point.
I would ask your readers to try the following thought experiment: my code uses a for_loop() so I need to check whether that algorithm has been patented in any form. Even restricting yourself to the US patent database, how could I be sure that that algorithm is not someone's invention? Then think of all the possible algorithms they may have used in one way or another. Can anyone honestly claim that they can meaningfully "defend and hold harmless" another entity? Which makes me question the value of the whole system.
It is difficult to provide solutions to the issues raised, but the first step in making anything better is to properly understand the problem. |
What is the scale of these issues? I was involved in a patent infringement case where our side spent $50m in litigation. Presumably the other side spent a comparable sum.
Do note, though, that in Alice v. CLS Bank the court ruled one cannot patent an abstract idea simply because it's running on a computer. For instance, implementing a bingo game in software is not patentable. Alice has limited software patents to some extent.
Larry R contributed this gem:
|
I have a vague recollection of seeing something like what I paraphrased below, a few years ago. Sadly. I can't provide a citation for the source:
This software is not warranted to perform as specified. This software is not warranted against failure. This software is not warranted against causing harm. In fact, this software is not warranted in any way whatsoever. This is pretty much the same warranty as offered by our competitors; they just use bigger words. |
|
In response to Muse 369's article about the Cortex M4 FPU, Scott Deary sent a very useful link. And multiple people pointed out that the M7's FPU does support double-precision math.
Paul Crawford wrote:
|
When you say "C standard requires sqrt() to use doubles" that is strictly speaking true, but generally most compilers (post C99 I guess) support sqrtf() for a single precision version that ought to be much faster if that is what you need in terms of precision (same for cosf() and similar trig functions).
More generally your timing measurements drive home the importance of using sufficient, but not excessive, precision for the code you are implementing if efficiency in memory use and/or execution speed is important. For past PC coding using the x87 FPU there was often very little difference in timing between float and double, but now that maths primitives are often done in SIMD instructions there is often a 1.5-ish speed difference. However, it is not always obvious if an algorithm is ill-conditioned and sensitive to numeric precision or not, so again you need to be conducting proper tests of the behaviour over all of your expected (and some unexpected) ranges of inputs.
Reading the introduction and relevant chapter(s) of the "Numerical Recipes" book (ISBN 987-0-521-88407-5) is a good start if you need to do any sort of non-trivial maths (though focused mostly on PC-style use), also you might also find this guy's blog interesting: https://randomascii.wordpress.com/category/floating-point/
The other thing you might want to add to the discussion is the really stupid/annoying aspect of some DSP/uC compilers where the presume you don't know what you are doing and decide to substitute float for double everywhere unless you find/change the compiler flags! For cases when you really do need the precision that is a serious bug, and something that may not be picked up by folk who do not have a very rigorous test suite for the intended floating point behaviour. |
I profiled sqrtf() and cosf() using IAR's compiler on a Cortex M4F running at 120 MHz, no cache and one wait state. Dave Kellogg suggested showing the timing numbers in a table instead of prose, so here is a summary of my results:
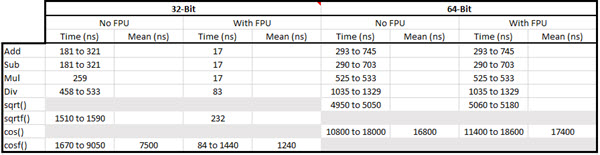
Values with a range are dependent on the arguments.
Values without a range are independent of the argument value.
I was puzzled that the FPU slowed down the cos() and sqrt() functions. Stephen Green explained:
|
If I try a floating point test using floats on my STM32F429 before the FPU is enabled I get a hard fault. i.e. it is using floating point instructions. If I change to using doubles I get no hard fault therefore the doubles are not using any floating point instructions. This explains your same timings for your doubles tests. |
Dave also recommended an important (though not easy) paper:
|
For the newer engineers in the field (particularly those without formal software training), please mention "What Every Computer Scientist Should Know About Floating-Point Arithmetic", by David Goldberg (ACM, March 1991). I used this link: https://www.itu.dk/~sestoft/bachelor/IEEE754_article.pdf |
|
I've been thinking about last year's Lion Air Flight 610 crash off Indonesia (and since writing this, last week's possibly similar accident in Ethiopia). While the official report isn't out, there's some reason to suspect that a malfunctioning angle of attack sensor contributed to the incident. It seems incredible that, if this is the way things are found to have happened, the instrumentation ignored many other sources of information that could have clarified the aircraft's attitude.
Brian Cuthie, a member of my Thursday night Boy's Night Out group, and I were discussing similar failures. He said that, due to the costs of verification, one can't make a system dependable through perfection. Rather, we make them dependable through resilience. It appears that the Lion Air Boeing was lacking that resilience (again, till the final report is issued this is only speculation).
I get heat from some readers about advocating for perfect firmware, or at least trying to approach that as a limit. They say that perfection is too expensive, and in, for instance, a cheap toaster, it can be cost prohibitive. Certainly, it's silly to use the onerous qualification strategy of DO-178C for a toaster. However, we have quantitative evidence that some methods lead to extremely high-quality code for less money than the strategies often used.
But I agree with Brian that resilience is important. Even critical in some systems, the Lion Air being an example.
Bill Gatliff, back in Muse 269 in 2014 addressed this brilliantly. He wrote:
|
It's often said that the one thing that makes embedded systems truly different from other types of computers is, we have to bridge the cognitive gap between our programs and the real world. Data processing happens in computer time, but sensors and actuators always happen in natural time, and our code and circuits stitch the two together.
As such, it's patently stupid to simply average incoming sensor data in order to estimate its value. And it's full-on negligent to use that averaging algorithm to "get rid of incoming noise". Sure, it'll work in the nominal cases, but what will happen if the wire gets disconnected altogether? An averaged stream of -1's is still... -1.
The correct solution is so natural, we don't even think of it. Consider the oil pressure gauge in the dashboard of your car. If that needle starts jumping about madly, we humans naturally start ignoring it because we know it can no longer be trusted: oil pressure doesn't jump around all that fast. We'll still log the problem for investigation, but we won't immediately halt the trip to summer camp. Or set the engine on fire.
The same is true for your speedometer, but in that case the seat of your pants gives you additional information that you don't have with oil pressure, coolant temperature, and other largely invisible values that are of the greatest here. Embedded systems don't usually wear pants, after all (but their operators often do, thankfully).
In the above examples, we humans aren't simply reading the gauges: we're also comparing those values against a mental model of what we _should_ be seeing, comparing all the available information against other types of sources, and trusting the ones that seem more plausible in the moment.
In temperature sensing for embedded work, we usually know the maximum rate at which a process can change temperature. When our sensor returns an error code or number that's way out-of-bounds, then, we shouldn't simply throw up our hands: we should switch to that estimation, instead. If nothing else, that will give us time to ask the operator if he wants to continue running, or shut the system down gracefully.
And speed? Most ground vehicles can't change velocity at a rate that exceeds 9.8 m/s2 unless they are mechanically coupled to the traction surface. There's the key parameter for your tracking algorithm right there.
The problem with the above examples are, to make them work we have to extract more information from our incoming data: we need the absolute value, but we also need to pay attention to the trend in case the data goes away. Yes, that's more development work, but I'd argue that the system is recklessly incomplete without it.
Our systems have to survive in the real world. And the real world doesn't stop just because you've lost a sensor or two. |
Resilience can be comprised of many things. Bill's approach is one. Another is the notion of mitigations, a common idea in safety-critical systems. If something does go wrong, what can the firmware do to at least place the system in a safe state?
I have seen medical systems where the mitigation code is as big as the main-line software, and vehicle software where the mitigation strategies extend to significant additional hardware to enter a safe though degraded mode. Typically a failure-mode and effects analysis identifies (hopefully) every possible problem that could arise, from bad sensor data to firmware failure. The team then writes code to mitigate against each of these to ensure safety.
In litigation surrounding the Toyota unintended acceleration case plaintiff's experts identified a "monitor" MCU located adjacent to the main processor whose purpose was to mitigate against improper actions commanded by that part. The experts found that the monitor code wasn't correctly implemented. No one would argue that mitigation code is easy, but in many cases it's important to invest the time and effort into getting it right.
In some safety-critical systems a small code change can require months of testing to meet the requirements of the applicable ISO/IEC standard. That would be ridiculous for a toaster. But if it were me, I might consider at least adding a fuse to mitigate against short circuits!
Perfection is elusive, and the real-world is one where things fail. I think reliable systems come from striving for perfection, verification (which is never enough by itself; you can't test quality into a system), and, where needed, employing mitigation strategies. No single approach is enough. |