|
||||||
You may redistribute this newsletter for non-commercial purposes. For commercial use contact jack@ganssle.com. To subscribe or unsubscribe go here or drop Jack an email. |
||||||
| Contents | ||||||
| Editor's Notes | ||||||
After over 40 years in this field I've learned that "shortcuts make for long delays" (an aphorism attributed to J.R.R Tolkien). The data is stark: doing software right means fewer bugs and earlier deliveries. Adopt best practices and your code will be better and cheaper. This is the entire thesis of the quality movement, which revolutionized manufacturing but has somehow largely missed software engineering. Studies have even shown that safety-critical code need be no more expensive than the usual stuff if the right processes are followed. This is what my one-day Better Firmware Faster seminar is all about: giving your team the tools they need to operate at a measurably world-class level, producing code with far fewer bugs in less time. It's fast-paced, fun, and uniquely covers the issues faced by embedded developers. Information here shows how your team can benefit by having this seminar presented at your facility. Latest blog: Engineer or scientist? |
||||||
| Quotes and Thoughts | ||||||
A safety culture is a culture that allows the boss to hear bad news. Sidney Dekker |
||||||
| Tools and Tips | ||||||
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past. Bit-banding is a really useful feature supported by most of the Cortex-M processors. It allows normal load/store operations to access individual bits in memory and I/O. Joseph Yiu's excellent The Definitive Guide to the ARM Cortex-M3 has a good description of it. Another is here. In the last Muse I suggested that firmware developers familiarize themselves with using oscilloscopes. Since then I ran across Rohde&Schwarz's excellent introductory guide. Did you know the CRT scope was invented in 1897? There's a picture of it in that guide. That's prior to vacuum tubes, or, at least, de Forest's Audion. Not new, but of considerable interest to firmware developers: The Power of Ten - Rules for Developing Safety Critical Code, by Gerard J. Holzmann. The paper discusses ten rules JPL uses to improve their code. From the concluding paragraph: "These ten rules are being used experimentally at JPL in the writing of mission critical software, with encouraging results. After overcoming a healthy initial reluctance to live within such strict confines, developers often find that compliance with the rules does tend to benefit code clarity, analyzability, and code safety." |
||||||
| Freebies and Discounts | ||||||
Tony Gerbic won last month's voltage standard. This month's giveaway is a piece of junk. Or rather, a battered and beaten "historical artifact." It's a Philco oscilloscope from 1946. The manual, including schematic, is here. I picked it up on eBay a few years ago, and while it's kind of cool, have no real use for the thing. It powers up and displays a distorted waveform, usually, but is pretty much good for nothing other than as a desk ornament. I wrote about this here. (The thing is so old I'd be afraid to leave it plugged in while unattended). Oh, that magnet on the right side? It's to position the beam!
Enter via this link. |
||||||
| Reusing SOUP | ||||||
Firmware is growing in size and complexity at a ferocious rate. Our only hope of keeping up with customers' demands is reuse, whether via commercial products, open source code, or reusing proprietary components. Often we don't know a lot about the hunk of code we'd like to incorporate, leading to the somewhat onomatopoeic acronym SOUP: SOftware of Unknown Pedigree. While most developers are not working on safety-critical code, we all want our products to be safe and reliable. It's instructive to look at how SOUP is handled in the world where a bug could kill someone. IEC 61508 is probably the most well-known standard for building safe systems. A portion of that document covers software. It identifies four Safety Integrity Levels (SIL) from 1 to 4, with SIL4 representing a system whose failure would be catastrophic. So, can SOUP be used in a system qualified to 61508? The answer is, "it depends." There are three routes to gaining certification for SOUP under 61508:
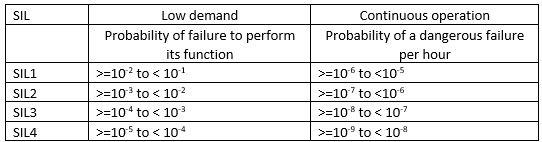
Option 1 is pretty much out for extant open source projects and most legacy code. Large code bases of any sort probably can't be qualified under option 3 due to the enormous costs involved. At higher levels (SIL3 and SIL4) few vendor-supplied packages will meet either of these qualifications, though some RTOS and comm stack providers do provide certifiable components today. That leaves option 2. To meet this requirement the integrator of the component (not a component's vendor) must demonstrate that it has been used in a similar role for a certain number of hours. Its uses and failures, if any, need to be recorded. Further, it must have "a restricted and specified functionality," which would seem to leave out big packages like desktop operating systems. Let's look into this a bit more deeply. The standard defines two kinds of systems. One that supports "low demand mode of operation" is generally turned off or is usually not performing any safety functions. A trivial example is a TV remote control that only comes to life when a button is pressed. Then there are "high demand or continuous mode of operation" devices: basically, those that run a safety function all of the time. An example might be a nuclear power plant controller, or, in some families, the TV set (assuming the TV is considered family-critical!). The standard's reliability requirements are:
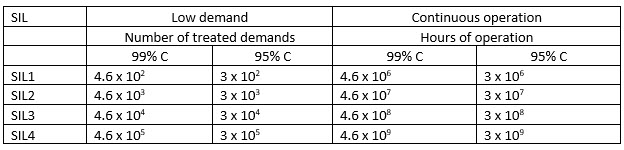
Formulas are provided to turn those figures into number of requests ("treated demands") or hours of operation to show a component is proven-in-use. Assuming 99% and 95% confidence levels, these work out to:
(C is confidence level). With billions of hours of use - recorded use - required, it's hard to see how any component could be qualified to SIL4 using the "proven in use" option. One could argue that if used in 100 million embedded systems you could divide those hours-of-operations by 100 million, making such certification feasible, but remember that the usage and failures of these must be recorded. In the safety world evidence must be presented to build a safety case that a component will work as promised. The use and failure log is that evidence. The key takeaway for non-safety-critical systems is that if you select a component and expect high reliability, either it must have been built using a very rigorous process, or it needs an awful lot of in-service time to gain confidence in it. Obviously, the range of safety and reliability requirements for embedded systems is vast. A smart toothbrush doesn't have the same requirements as an engine control unit, which in turn can be less reliable than, say, a nuclear weapon's permissive action link. (There's a lesson here in end-runs around safety-systems, given that the PAL key was reputedly 00000000 for years.) |
||||||
| Advice to a Young Developer | ||||||
Daniel Wisehart had ideas on advice to young developer in addition to what I wrote:
Dave Kellog wrote:
|
||||||
| On Legacy Code | ||||||
Last issue I wrote a bit about legacy code. Readers had some interesting thoughts. Tom Mazowiesky wrote:
Steve Peters sees a parallel to hardware:
Lars Pötter contributed:
This is a good point. The second law of thermodynamics says that disorder increases in closed systems. Entropy increases. Programs are no more exempt from this depressing truth than the expanding universe. Successive maintenance cycles increase the software's fragility, making each additional change that much more difficult. Software is like fish. It rots. Over time, as hastily-written patch after panicked feature change accumulate in the code, the quality of the code erodes. Maintenance costs increase. As Ron Jeffries has pointed out, maintenance without refactoring increases the code's entropy by adding a "mess" factor (m) to each release. That is, we're practicing really great software engineering all throughout a maintenance upgrade... and then a bit of business reality means we slam in the last few changes as a spaghetti mess. The cost to produce each release looks something like: (1+m)(1+m)(1+m)...., or (1+m)N, where N is the number of releases. Maintenance costs grow exponentially as we grapple with more and more hacks and sloppy shortcuts. This explains that bit of programmer wisdom that infuriates management: "the program is too much of a mess to maintain". But many advocate starting release N+1 by first refactoring the mess left behind in version N's mad scramble to ship. Refactoring incurs its own cost, r. But it eliminates the mess factor, so releases cost 1+r+r+r..., which is linear. This math is more anecdotal than accurate, but there's some wisdom behind it. Luke Hohmann calls this "post release entropy reduction." It's critical we pay off the technical debt incurred in being abusive to the software. Maintenance is more than cramming in new features; it's also reducing accrued entropy. |
||||||
| Another Ideal Diode | ||||||
A lot of readers responded to the Ideal Diode in the last Muse. It seems many such products are available. Enrico wrote:
|
||||||
| This Week's Cool Product | ||||||
Semmle sells a tool called QL, which allows developers to ask deep questions about their code. QL treats the code as data, and, like a database, provides a mechanism so users can construct deep queries about the code. Sounds sort of like marketing hand-waving, until one looks at some of their case studies. Engineers at JPL found a bug in the Mars Curiosity Rover firmware which could have resulted in the loss of the mission. Instead of just fixing it and moving on, in 20 minutes they constructed a QL query which found the same problem in 30 other places! That sort of engineering appeals to me: learn something, then assume you could have made a similar mistake, so hunt for more instances of it. I haven't used it, and can't help but wonder if considerable training is needed about the query language, but always find it heartening to discover more sophisticated tools for error-removal. Note: This section is about something I personally find cool, interesting or important and want to pass along to readers. It is not influenced by vendors. |
||||||
| Jobs! | ||||||
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intent of this newsletter. Please keep it to 100 words. There is no charge for a job ad. |
||||||
| Joke For The Week | ||||||
Note: These jokes are archived here. Not a joke, but funny. Jeanne Petrangelo sent this: A woman operating a slot machine in New York "won" $42,949,672.76. Note that 232 is 4,294,967,276. Ya think the software glitched? The casino offered her two bucks and a free dinner instead of $232/100. |
||||||
| About The Embedded Muse | ||||||
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. |