| ||||
You may redistribute this newsletter for non-commercial purposes. For commercial use contact jack@ganssle.com. To subscribe or unsubscribe go here or drop Jack an email. |
||||
| Contents | ||||
| Editor's Notes | ||||
Last issue I mentioned my new blog. Many readers asked for a RSS feed of it, which is now active. After over 40 years in this field I've learned that "shortcuts make for long delays" (an aphorism attributed to J.R.R Tolkien). The data is stark: doing software right means fewer bugs and earlier deliveries. Adopt best practices and your code will be better and cheaper. This is the entire thesis of the quality movement, which revolutionized manufacturing but has somehow largely missed software engineering. Studies have even shown that safety-critical code need be no more expensive than the usual stuff if the right processes are followed. This is what my one-day Better Firmware Faster seminar is all about: giving your team the tools they need to operate at a measurably world-class level, producing code with far fewer bugs in less time. It's fast-paced, fun, and uniquely covers the issues faced by embedded developers. Public Seminars: I'll be presenting a public version of my Better Firmware Faster seminar outside of Boston on October 22, and Seattle October 29. There's more info here. Onsite Seminars: Have a number of engineers interested in this? Bring this seminar to your facility. More info here. |
||||
| Quotes and Thoughts | ||||
"You can do it right, or you can do it over again. If a software team stresses quality in all software engineering activities, it reduces the amount of rework that it must do. That results in lower costs, and more importantly, improved time-to-market." - Roger Pressman |
||||
| Tools and Tips | ||||
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past. I stumbled across Chris Svec's excellent intoduction to using FreeRTOS. From Gerard Duff:
|
||||
| Freebies and Discounts | ||||
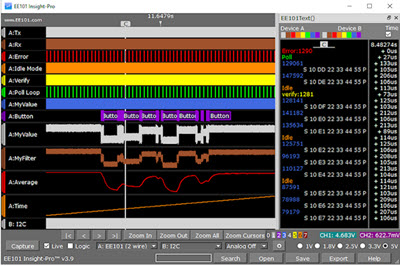
This month we're giving away a $369 EE101 Insight-Pro embedded system debugger and analyzer. The company sent me one but I'm not going to have time to review it. It's a combination oscilloscope, logic analyzer, protocol decoder and more.
The contest closes at the end of August, 2018. Enter via this link. |
||||
| Perils of Using Hardware in Asyncronous Sampling | ||||
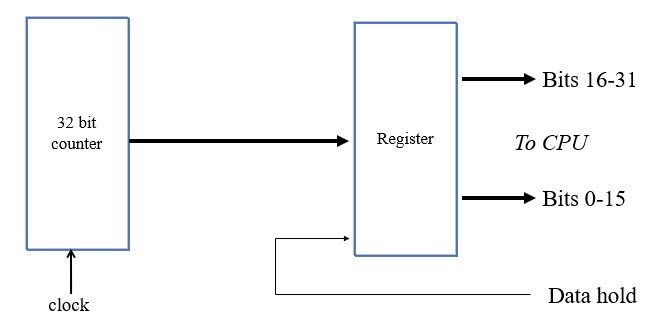
Last issue I described an unfortunately-common bug in handling input devices which are wider than the processor's bus. Two or more reads are needed and, since the input may change between those reads, subtle bugs may emerge. It's tempting, especially if you are a EE, to try a hardware-based solution. That may or may not work and requires a careful analysis of the entire system. To recapitulate last week's column, one common situation is where a 16 bit processor is reading a 16 bit timer to keep track of elapsed ticks. It's a way of measuring time, where time is a number of milliseconds since power-up or some event. Generally a 16 bit counter will overflow rapidly so the code adds another 16 bits in RAM; that value is incremented every time the timer overflows. The elapsed time is therefore the concatenation of the value in RAM and that in the hardware timer. As I showed last week, in this situation perils abound. A tempting solution is to build a 32 bit timer that counts clocks, and then to latch that value into a register when the processor wants to know the time. Latched, the CPU has all the time it needs to issue two reads to that latch and all of the insidious problems go away. A block diagram looks like this:
Before reading the data the code issues the "data hold" signal that transfers whatever is in the counter into the latch. Alas, there's only one case where this is reliable, which is when that signal is synchronous to the clock feeding the timer. If you can't guarantee that these are synchronous, sometimes both may transition at about the same time. If the register changes just as the latch is commanded to save that data, what do you think will happen? Well, no one knows. The result latch's output is likely to oscillate for a short period of time (nanoseconds) and then settle to random values. This is a well-known situation in hardware design called metastability. Every latch has a setup and hold time. The input must be stable for a short time prior to and after the "data hold" signal's transition. "Short time" is generally on the order of nanoseconds depending on the technology used. TI's super-fast 74AUC logic pegs that at about 0.5 ns. Slower logic is less forgiving. You may think that with such short windows the odds of failure are remote, but Here There Be Dragons! Over the course of days, weeks or years of operation millions or billions of opportunities for metastable behavior will occur. Why would these signals be asynchronous? If the clock comes from another CPU, or perhaps some other off-board signal, expect problems. Figure any signal not derived from the CPU's clock is suspect. Short of synchronizing these signals there are few hardware solutions to metastability. One might be to insert a FIFO between the 32-bit timer and the MCU. Or, one could issue "data hold" and read the latch twice, looking for monotonically-increasing (or constant) results. But that's pretty much the same solution I proposed last week for a software-only version. All of this extra hardware doesn't do much other than to clutter the PCB and increase power dissipation. The bottom line is that even what appear to be simple problems like reading a timer can have subtle tribulations that can only be resolved by careful design and analysis. Good engineers are alert to worst-case conditions and take appropriate corrective action. But hopefully that's done before these sort of impossible-to-troubleshoot bugs surface. One of the best references on metastability is Ti's report SDYA006: "Metastable Response in 5-V Logic Circuits" |
||||
| Whether 'Tis Nobler to Initialize or Not | ||||
Eric Krieg wrote:
The MISRA rules don't address this substantially, though rule 9.3 states: "Arrays shall not be partially initialized." The Barr Group standard's rule 7.2.a is "All variables shall be initialized before use". I quickly (maybe too quickly) looked through the C99 standard and found at 5.1.2 "All objects with static storage duration shall be initialized (set to their initial values) before program startup. The manner and timing of such initialization are otherwise unspecified." It's not at all clear to me that this means set to zero. 6.2.4 appears to indicate that arrays are not initialized: "The initial value of the object is indeterminate." Richard Man of Imagecraft, an embedded compiler vendor, said all C-compliant compilers set the BSS to zero, but mentioned that sometimes developers do tricky things in the startup code that might cause problems. As an old-timer who grew up on assembly language my practice has always been to initialize every variable prior to first use, regardless of language. One could zero out the entire BSS in the startup code, but I find an explicit assignment statement clearer. |
||||
| Increasing the Resolution of an ADC | ||||
... Or, When Noise is GoodSuppose you have a signal constrained to zero to five volts, that you want to sample with a resolution of 0.0025 mV. And that MCU only has a ten-bit analog-to-digital converter. Drats! (Note that a ten bit ADC resolves 1024 distinct "steps", in this case corresponding to about 0.005 V) An 11-bit job would provide just enough steps to get to 0.0025 mV, but even that's not enough as there's at least a half bit of uncertainty in the converter. So you sigh, drop in a 12-bitter, and listen to the boss berate you for the extra parts costs. But there may be other options. Oversampling can provide extra Effective Number Of Bits (ENOB, a common acronym in ADC circles). Read the ten-bit ADC many times and average the result. If there's some system noise - at least half a bit worth - the averaged result will have the effect of extending the converter's ENOB. Generally we don't like noise, but in this case it has the effect of dithering the analog signal enough so the ADC can peer deeper into the signal. If the input were perfectly devoid of any cacophony, the ADC will read exactly the same voltage every time and you won't gain any ENOB. For every four averaged samples you'll get one additional ENOB. So for n additional ENOB, you'll need 4n samples. The downside is the added time needed to get these samples. If your ADC is fast enough, that may not be a problem. Remember, to achieve good signal fidelity you'll need to sample at the Nyquist frequency or faster, which is twice the highest frequency in the signal. So if you can sample at fos: fos = 4n * fnyquist ... then you'll get n additional ENOBs with no loss in overall system update rate. There are two (at least) excellent papers about this with examples and more detail:
|
||||
| Jobs! | ||||
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intent of this newsletter. Please keep it to 100 words. There is no charge for a job ad.
|
||||
| Joke For The Week | ||||
Note: These jokes are archived here. Axel Wolf sent this gem. I had to look it up, but in this context MCU means Marvel Cinematic Universe. I especially like the paired "MCU" and "Core".
|
||||
| Advertise With Us | ||||
Advertise in The Embedded Muse! Over 28,000 embedded developers get this twice-monthly publication. . |
||||
| About The Embedded Muse | ||||
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. |