|
||||
You may redistribute this newsletter for non-commercial purposes. For commercial use contact jack@ganssle.com. To subscribe or unsubscribe go here or drop Jack an email. |
||||
| Contents | ||||
| Editor's Notes | ||||
Due to popular demand and an insatiable urge to write, I've started a blog. Latest entry: USB v. Bench Scopes. This Fall we'll be doing a Better Firmware Faster seminar in Boston and one in Seattle - more info soon. I'm also getting interest in presenting it in Australia (maybe Melbourne) and New Zealand. To gauge interest in it, please email me if that's something you'd like to attend. Marybeth recently told me that we've done 400 of these seminars for companies at their locations and 48 public versions over the last two decades. Go here for information about bringing it to your company. |
||||
| Quotes and Thoughts | ||||
"Complex systems usually come to grief, when they do, not because they fail to accomplish their nominal purpose. Complex systems typically fail because of the unintended consequences of their design." - Michael Griffin |
||||
| Tools and Tips | ||||
|
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past. Responding to a link to an article about dealing with capacitance when using I2C, Nash Reilly wrote:
I was going over some code recently and found a password stored in malloc-ed memory. That was quickly freed, so the password was deleted. But, of course, it wasn't. The password was still in the heap, potentially visible if those locations were ever returned to fulfill an allocation request. The code's author should have scrubbed those locations first, and then freed the memory. Jean Labrosse has a worthwhile article about measuring execution time on Arm MCUs. |
||||
| Freebies and Discounts | ||||
David Flagg won the Siglent 2 channel scope in last month's contest. This month we're giving away a $369 EE101 Insight-Pro embedded system debugger and analyzer. The company sent me one but I'm not going to have time to review it. It's a combination oscilloscope, logic analyzer, protocol decoder and more.
The contest closes at the end of August, 2018. Enter via this link. |
||||
| On Operator Precedence | ||||
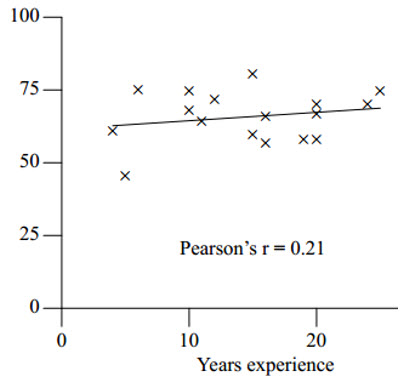
Michael Pollan's advice about eating is concise: "Eat food. Not too much. Mostly plants." In a similar vein, I'd suggest about C code: "Use parenthesis. More than you'd think. Clarify expressions." In an experiment, Derek Jones found that developers are often confused about precedence rules. He tested a number of developers about these rules, and found that regardless of experience, we score poorly. The following graph shows the percentage of incorrect answers to precedence questions versus years of experience:
Frankly, why would I want to clutter my mind with what in some cases are quite arcane rules, like & is higher than ^? The company's firmware standard should mandate that all expressions using operators be enclosed in parentheses. That is: if(x && 3 == y)... ...should be illegal. Better: if((x && 3) == y)... And do use tools that will capture these sorts of mistakes. Lint, for instance, will throw a warning when it sees a construct like: if(rap & dissonance == 0)return 0; Parentheses are our friends. |
||||
| Firmware Process Improvement | ||||
From time to time companies ask me to root through their firmware development processes and suggest ways to make improvements. The goal is usually to improve quality, but the ancillary benefit of shortened schedules often results. This effort goes under the well-known moniker "Software Process Improvement", or SPI. Often the effort comes from senior management's frustration with delivered defects. In some cases these have cost the company millions in recalls or lost sales. If it weren't for the NDAs I could tell you tales that would make you blanch. It's interesting that in no small number of these cases the companies feel their processes are state-of-the-art because they adhere to an ANSI or ISO standard. They're shocked when it turns out that though the standard is being met, more or less, the teams aren't using leading-edge processes so errors are leaking out into the field. SPI starts with interviewing at least a subset of the team members to gain an understanding of what each person actually does, and how they approach the job. I always ask what defined processes are used and how each goes about meeting those mandates. Without exception these interviews show that, yes, there is some defined process, but different people use only a subset of it. It's common to find the company has, for instance, a firmware standard or three that exist, well, somewhere, maybe, but some of the team members haven't seen it in years. Or that unit tests are employed with rigor... by a third of the team. Requirements are completely defined by a committee, but that document has been obsolete for months or years. While every SPI effort uncovers different things, the following list is common:
These are all fixable given two conditions. First, management must support the SPI effort, give the team the resources needed, hold developers accountable, and be committed to the needed changes over the long-term. Second, the team must be engaged and willing to try new things. When my kids were new drivers I asked them to, throughout their driving career, be at least occasionally introspective about their behind-the-wheel behavior and skills. "Why didn't I use the turn signal at that intersection?" "Maybe I was following that motorcycle too closely." Unless we're willing to believe that we can improve our skills and make better decisions, we won't. The same goes for software engineering. Continuous improvement is the mantra behind the quality movement, and should be our goal as well. Recommended reading:
|
||||
| Asynchronous Sampling | ||||
A lot of systems track relative time by using a hardware timer that counts clock pulses. In this case "time" is measured in ticks. This is a very simple bit of code, code that more often than not is implemented naively and incorrectly. Suppose you're using a 16-bit microcontroller. The on-board timer is probably also two bytes wide. There might be a prescaler that increments the timer only every so many clock pulses. For millisecond resolution with a 1.024 MHz clock a ten-bit divider will add one to the timer every millisecond. But a 16-bit timer driven at this rate rolls over about once a minute so usually the code is configured to generate an interrupt on each overflow, the interrupt incrementing a value in memory. The time in ticks is that memory value concatenated with the current value in the hardware timer. The code generally looks like this: uint32_t timer_read(void){
uint32_t low, high;
low =inword(hardware_register);
high=timer_high;
return ((high<<16) + low);
}
... where timer_high is the value incremented by the interrupt service routine. What could be simpler? Alas, this code simply does not work. Or worse, it will behave properly most of the time, only wreaking havoc sporadically in a non-reproducible fashion that's just about impossible to reproduce. Let's break it down with a concrete example. Suppose no interrupts have occurred; the system hasn't been running too long, but it has been up for about a minute so the hardware timer is all ones. Now the situation is this: uint32_t timer_read(void){
uint32_t low, high;
Note that at this point the timer is 0xffff and timer_high == 0. low =inword(hardware_register); low is 0xffff. But now something insidious happens. The timer rolls over to 0x0000 and an interrupt occurs. That interrupt adds one to timer_high which is therefore 0x0001. high=timer_high; low is still 0xffff but high is 0x0001. return ((high<<16) + low); The result? Function timer_read() returns 0x1ffff, which is twice the real value. In a simple case perhaps the time is just off and there are no serious side-effects. But suppose math is being performed to compare the returned value with other times. Negative times might happen. Testing will probably not elicit the very random failure. There's really no ex-post facto way to capture these sorts of errors so careful design coupled with code reviews are your best defense. A simple solution is to stop the timer before reading it, but that will cause the system to lose ticks. Disabling interrupts won't help as between the read of the value in memory and the hardware timer the latter could roll over, giving us 0x0000 instead of a more reasonable 0x10000 or 0xffff. One approach is to call timer_read twice and look for monotonically-increasing values. Alternatively, timer_read could itself look for a timer overflow and make an appropriate correction. There are many situations like this where two or more reads are needed to access a value wider than the processor's word length. For instance, if an 8-bit processor is reading a 12-bit parallel shaft encoder that CPU will need to issue two reads to get the entire encoder's input. But the shaft is turning; the two reads could give the same sort of mishmash we saw above, and a similar sort of corrective strategy must be employed. Sometimes, when this is pointed out people think about their wide analog to digital converters. An 8- or 16-bit CPU trying to access a 20 bit ADC will take two or more reads. In this case, as Douglass Adams said "don't panic." ADCs have an internal latch which is updated after a conversion is complete, so there's no chance of this sort of situation happening. |
||||
| Jobs! | ||||
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intent of this newsletter. Please keep it to 100 words. There is no charge for a job ad. |
||||
| Joke For The Week | ||||
Note: These jokes are archived here. First Two Laws of Computer Programming 1) Never trust a program that has not been thoroughly debugged. 2) No program is ever thoroughly debugged. |
||||
| Advertise With Us | ||||
Advertise in The Embedded Muse! Over 28,000 embedded developers get this twice-monthly publication. . |
||||
| About The Embedded Muse | ||||
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. |