|
You may redistribute this newsletter for non-commercial purposes. For commercial use contact jack@ganssle.com. |
| Contents |
|
| Editor's Notes |
Did you know it IS possible to create accurate schedules? Or that most projects consume 50% of the development time in debug and test, and that it's not hard to slash that number drastically? Or that we know how to manage the quantitative relationship between complexity and bugs? Learn this and far more at my Better Firmware Faster class, presented at your facility. See https://www.ganssle.com/onsite.htm for more details.
|
| Quotes and Thoughts |
The quote in the last issue was: "More than 80 percent of software bugs will be found in less than 20 percent of software modules. Pareto Principle as modified by Capers Jones."
John Black sent this corollary: More than 80 percent of software bugs are generated by less than 20 percent of the programmers. |
| Tools and Tips |
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past.
How do they achieve a billion samples per second? According to this tear-down the ADC is an HMCAD1511, which is an 8-bit four-channel unit. With two channels enabled the sample rate falls in half. The chip includes programmable gain amplifiers to implement at least some of the variable amplitude control needed by a scope. It communicates with the Zynq using high-speed LVDS. According to the datasheet it uses 8 ADCs, no doubt each sampling at up to 125 Ms/s. That's 8 ns/sample, which is pretty impressive.
Speaking of scopes, last issue I asked if anyone was using those inexpensive units from Tektronix and/or Keysight. Hendrik Lipka sent a link to a review he wrote about Tek's $520 TBS1052B-EDU. Andy Neil sent a link to a road test for the Keysight DSOX1102G that's going on, though it's now too late to sign up to be part of the test.
Finally Chris Eddy has some comments about a couple of low-cost scopes:
|
I have some thoughts on the low cost range scopes that you mentioned.
Many years ago (~15) I bought a GW Instek GDS-810, 2 channel 100MHz color. I recall at the time that I could get the scope for less than an 80's vintage mono Tektronix off of Ebay. On occasion I would use the RS232 feature to capture some data with a PC program that was not very well written. When the scope quit 2 years ago, and I could not repair it's power supply, I wrangled an off the shelf supply into the chassis and patched the voltages into the right places to make it live again. I call it the FrankenScope.
Move ahead to 2 years ago (when the above scope was dead) and I bought an Owon SDS7102-VGA. It is a 2 channel 100MHz model. To be honest, it does not do that much more on the screen than the Instek unit, but it has all of the extra communication features. Unfortunately I have not been able to get them to work. The Ethernet refuses to work in my shop with the Verizon router. I ruled it down to the router by setting up a separate router, where the scope will then communicate. I also tried the USB and Flash stick features, and could not get them to work, although I did not spend as much time troubleshooting. I suspect that when these "extras" are designed in, the design team tests them against one setup, and does not thoroughly test these features.
In summary, I like the convenience of a low cost 2 channel that is easy to use, but I suspect that any advanced users that need the communications and storage features may be sorely disappointed. |
|
| Freebies and Discounts |
The mantra of Ada programmers is "if you can make the darn thing compile at all, it will work," because the compiler just doesn't allow for most silly mistakes. An Ada variant, SPARK, is even more demanding. SPARK's philosophy is "correctness by construction." Bug rates in programs written in the language are unbelievably low.
This month's contest giveaway is a copy of the book Building High Integrity Applications With SPARK, by John McCormick and Peter Chapin. One lucky Muse reader will win this at the end of April when the contest closes.

Enter via this link. |
| More on Operator Precedence |
In response to the article last issue about operator precedence, a number of people wrote in about one snippet of code. Paul Crawford's response was spot-on:
|
> That means, for an integer N,
> N<<k = N x 2k // Efficient multiplication
> N>>k = N / 2k // Efficient division
That is a very useful trick and what you have written is *almost* correct.
What is wrong? Well if you use the efficient division trick with a negative signed number it works all the way down until you get to -1 and then further right-shift operations keep it at -1, it never goes to zero as the signed-bit is extended on every shift.
So you have two simple examples:
-8 => -4 => -2 => -1 => -1 (last step maybe a surprise!)
This may be a problem in some cases, as a very common trick to implement a fractional scale in integer maths is this sort of thing:
y = (x * num) / den;
Which is close to the floating point result you would get for
y = x * (num/den);
But which fails for integer maths for exactly the sort of reasons that operator precedence matters. It can also fail for the less-obvious reason of the intermediate product (x * num) exceeding the numerical range of the data type used.
To speed up the above for intensive tasks such as signal processing you might choose 'den' to be a power of 2, in which case you get:
y = (x * num) >> log2den;
Again, for +ve its great and for most -ve also great, and saves you a potentially expensive divide instruction. However, if you really must get it right and can accept an average of "3 instructions" instead of 1 for the shift, you can do something like this:
tmp = x * num;
if(tmp < 0) {
y = -(-tmp >> log2num);
} else
y = tmp >> log2num;
}
So for tmp >= 0 it is two "operations" (test, then shift) while for tmp < 0 it is 4 (test, sign reverse, shift, sign reverse).
Plus probably one instruction for branching as well, etc. That aspect depends on the CPU architecture and so on, as it could be anywhere between 0 and 5-10 clock cycles in practice! It is still likely to be faster than a divide, but if speed mattered that much you would try both the obvious and the shift-based approach and choose the best. |
And Luca Matteini wrote:
|
as a long time C programmer, I read with interest the first lines on the article about C operators precedence. Then, beside finding funny and interesting how was created that rhyme to help remembering them, I couldn't think anything different that the posed problem is wrong, in my humble opinion.
If I happen to find myself writing an expression like the cited
a=9<<2^a-a&a*2%3+2|9/2>>1<<2;
best case is I'm trying to run an obfuscated code contest! Otherwise my code is going to be insanely wrong and unmaintainable.
Maybe I just work with low to medium complexity systems, but I don't think I'd never need something that hard to read, whatever my competency in operators precedence is.
Ideally I would simplify expressions with well commented intermediate variables, letting the compiler do the hard work for me. I'd also add some white spaces, because at a later time I'll need to read well variable names and operators.
I would put parenthesis where strictly needed to enforce precedence, plus a few ones when for some readability reason I want to emphasize what's going on, with the algorithm.
Moreover, even if the expression keeps being an integral type I would try to separate it in sub-expressions when complex and using the conditional "?:", unless clear/immediate as in
limit = value > 100 ? 100 : value;
Around mid 80s I found a small booklet with a computer magazine, a short guide to C language. What impressed me the most was a paragraph about complex pointer dereferencing, where they cited a source code line example, with a dozen parentheses and cast operators to show how complex could become.
The good question is again "why?". Any well written code should first reduce indirection levels, and not use something very complex "just because it can be done"(...) or because it's "legal", like
int func(void) { return 1; }
int a_prime(void)
{
int (* fn)(void), i;
fn = func;
i = (*************fn)() + (***fn)();
return i;
} |
|
| Another Semi Vendor Fail |
Previous issues of the Muse have contained complaints about vendor-supplied software libraries. I hear these tales all the time! In an effort to shame the vendors into upgrading their offerings, here's another take, this one from Christian Schneider:
|
Today, I had one of the worst experiences with an MCU ecosystem in my career and I would like to share it with the TEM audience.
Last week, our intern came to me with a "strange behavior" problem in his SiLabs BlueGecko project. His task was to implement our own UART bootloader protocol into the EFR32BG1 series MCU based on the STM32 implementation.(Another colleague had done the application based on a SiLabs example project and just left the SiLabs bootloader in but for compatibility with production equipment we need to have our own protocol)
He had made some typical newbie mistakes so I took some time to explain him the typical layout of a Cortex-M binary with initial stack pointer and reset vector address and showed him how to use the SCB->VTOR register to move the interrupt vector table.
After fixing all the issues, we went into testing and debugging and it still hung up so I had to dig deeper into the SiLabs ecosystem and what I found did not make me happy.
After hours of debugging, here is what we found out: SiLabs uses a table of metadata linked at the start address of each binary instead of the vector table like it is typical in the Cortex-M world. The Bluetooth stack is a BLOB that also happens to contain a portion of bootcode. The bootloader has to jump to this bootcode that looks for a table in the application code with a special name containing the reset vector and jumps to the application code. Each stage implicitly expects the stage before to do some hardware initialization, if this is not done, I just hangs or gives a HardFault somewhere in the BLOB. You have to run through all stages to get into your application.
The problem is: Nothing of this is documented at all. The information you can find in the PDFs is high-level and does neither describe the boot process nor does it show a way how to implement your own bootloader. To access the library examples, you are forced to install the whole Eclipse based IDE. (I spent half a day with proxy settings before giving up and downloading the examples at home)
This shows two things that seem to become more and more common:
1. BLOBs for bootcode and stacks: Ok, I understand that silicon vendors don't want to disclose their IP but at least these things should be documented and give error codes if an error occurs and they should not implicitly rely on a certain state of the MCU. (If the PLL is nor running, either give an error code or get it running but don't crash).
2. Example code is often either trivial (Blinky_HelloWorld) or a highly complex finished application and all are marketed as 1-click-to-running-application. The first doesn't help at all and the second makes it almost impossible to learn something from it. I am often missing examples that show a specific feature of the MCU like a special timer mode in an uncluttered and clear fashion. |
|
| This Week's Cool Product |
Linear Technology just announced a 32 bit - that's right, 32 bit - ADC. With a Vref of 2.5 to 5.1 volts, the LTC2500-32 can resolve down to a nanovolt. I'm having a hard time thinking of an application that would require such resolution. And, the datasheet lists various linearity and offset errors measured in the ppm range, which would seem to swamp the device's resolution. Linear hasn't responded to my questions about applications for the part.
But 32 bits is pretty darn cool.
Interestingly, there are two outputs. One is a filtered 32 bit value with a 61 sample/second rate. The other contains 24 bits of differential data between the two inputs plus 7 bits of common mode information, updated at 1 Msps.
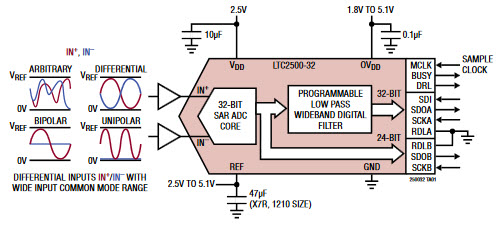
Digi-Key lists these at $55 in singles, dropping to $43 in 2500 lot quantities.
One shudders at the thought of designing a PCB quiet enough to take advantage of this resolution.
It turns out several 32 bit ADCs exist, such as the ADS1263 from TI and the AD7177 from Analog Devices (which owns Linear Tech). These two datasheets have tables listing effective number of bits depending on various situations, like conversion rate. It appears unlikely one could actually get 32 bits of resolution from the devices.
Note: This section is about something I personally find cool, interesting or important and want to pass along to readers. It is not influenced by vendors. |
| Jobs! |
Let me know if you’re hiring embedded
engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intent of this newsletter.
Please keep it to 100 words. There is no charge for a job ad.
|
| Joke For The Week |
Note: These jokes are archived at www.ganssle.com/jokes.htm.
WARNING: Non-maskable interrupt handler SPOUSE has unbounded execution time and unrestricted invocation frequency. |
| Advertise With Us |
Advertise in The Embedded Muse! Over 27,000 embedded developers get this twice-monthly publication. . |
| About The Embedded Muse |
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and
contributions to me at jack@ganssle.com.
The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get
better products to market faster.
|



