|
|
||||||||||||||||
You may redistribute this newsletter for non-commercial purposes. For commercial use contact jack@ganssle.com. |
||||||||||||||||
| Contents | ||||||||||||||||
| Editor's Notes | ||||||||||||||||
Did you know it IS possible to create accurate schedules? Or that most projects consume 50% of the development time in debug and test, and that it's not hard to slash that number drastically? Or that we know how to manage the quantitative relationship between complexity and bugs? Learn this and far more at my Better Firmware Faster class, presented at your facility. See https://www.ganssle.com/onsite.htm for more details. |
||||||||||||||||
| Quotes and Thoughts | ||||||||||||||||
"The problem with the future is that it keeps turning into the present." – Bill Watterson |
||||||||||||||||
| Tools and Tips | ||||||||||||||||
|
||||||||||||||||
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past. Several people responded to Dave Kellog's query about a more MISRA-compliant printf. Scott Nowell of Validated Software wrote:
Dave Hylands sent in his printf:
Gary Lynch has his own approach:
Sergei Akhmatdinov suggests ee_printf:
Ed Sutter wrote:
Mat Bennion's approach is to avoid printf altogether:
In the last Muse Daniel McBreaty passed along a bit-banging UART for a PIC. I wondered if anyone had implemented one of these using an interrupt rather than timing loops. Martin Glunz replied:
Tim Wescott responded to my comments about C swallowing all sorts of legal but often-wrong code:
|
||||||||||||||||
| Freebies and Discounts | ||||||||||||||||
Win a copy of the book Embedded Software Development for the Internet of Things. The contest runs till the end of March. Enter via this link. |
||||||||||||||||
| The Cortex-M MPU, Part 3 | ||||||||||||||||
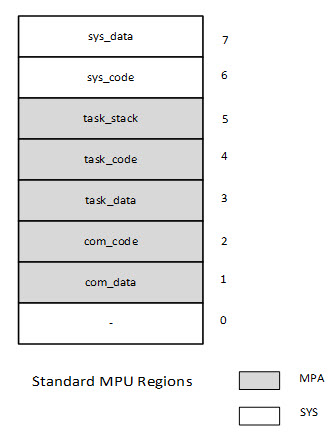
In 1985 Intel came out with the 386 processor, which had an on-board memory management unit. Most developers programmed it to give a flat 32 GB address space. At the time - and in the 32 years since - I thought the MMU was a huge gift to developers. It gave us a way to make software that was more robust and secure. Alas, the microcontroller space really hasn't had that sort of resource till recently, when ARM came out with their memory protection unit (MPU). In my opinion, the MPU is a boon to developers, one that is still too underutilized. Ralph Moore has been writing about using it. Here's Ralph Moore's third and final installment about using the Cortex-M MPU. Part 1 is here and part 2 here. IntroductionAs I noted in my previous blogs, "Working With the Cortex-M MPU" and "MPU Multitasking", embedded systems are being drawn into the IoT and thus security in the form of protection of critical system resources is becoming increasingly important. The previous blogs discussed how to define MPU regions and Memory Protection Array (MPA) templates using the regions and then how these are used to enable MPU operation in a multitasking environment. The resulting MPU format and a step-by-step procedure to convert existing software to MPU protection is the subject of this blog. MPU FormatThe following MPU format results from previous discussions:
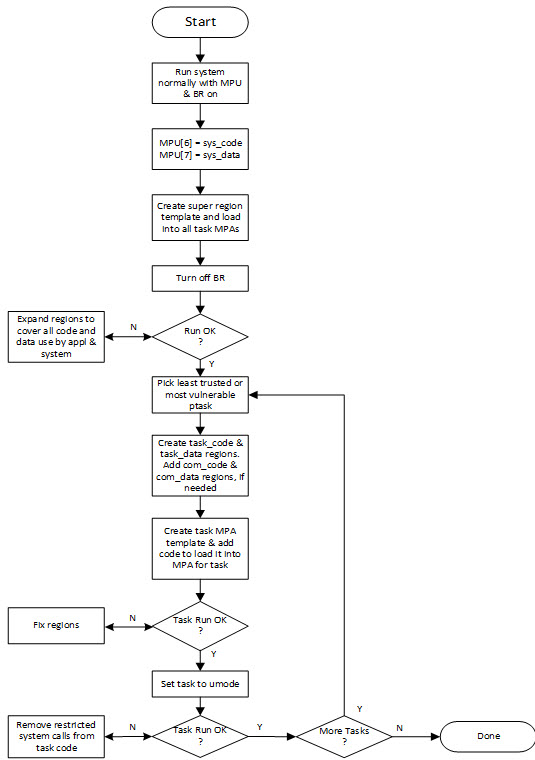
This seems to be a good format for the MPU. The top two regions contain the Main Stack and code for handlers and ISRs, respectively. These are privileged regions that are present for all tasks. The shaded regions correspond to Memory Protection Arrays (MPAs) that are loaded when tasks are dispatched. An MPA may be unique to a task or may be shared between a group of tasks. MPAs apply to both privileged tasks (ptasks) and unprivileged tasks (utasks). The bottom region (0) is available for a system region, such as an RO region for C libraries, tables, and text strings, or it could be added to the MPA if more regions are needed for tasks. In the event of a region overlap, the higher number region's attributes prevail. Step by Step ConversionThis blog presents a step-by-step procedure to provide MPU security to late- and post-project systems. It, of course, can also be applied to new projects. The goal is to achieve the reliability, security, and safety that modern embedded systems require. The following flow chart provides an overview of the porting process:
StartTo start, it is assumed that the RTOS library includes the MPU-Plus™ files. Add a call to sb_MPUInit() near the beginning of the startup code and temporarily disable loading MPU[6] & [7] in it. This turns on the MPU and enables its Background Region (BR). The application should run normally with these changes. System RegionsNext, define .sys_code and .sys_data sections. sys_code should contain all handler and ISR code. This is done as in the following example for assembly code:
SECTION `.sys_code`:CODE:NOROOT
THUMB
smx_PendSV_Handler:
MPU_BR_ON ; turn on MPU background region
MPU_BR_OFF ; turn off MPU background region
cpsid f
sb_INT_ENABLE
pop {pc}
and for C code: #pragma default_function_attributes = @ ".sys_code"
void sb_OS_ISR0(void)
{
MPU_BR_ON(); /* turn on MPU background region */
... /* ISR body or call ISR function here
MPU_BR_OFF(); /* turn off MPU background region */
sb_OS_ISR_EXIT();
}
#pragma default_function_attributes =
The BR macros were discussed in the previous blog. Then in the linker command file: define block sys_code with size = 4096, alignment = 4096 {ro section .sys_code};
define block sys_data with size = 512, alignment = 512 {block CSTACK};
Of course, the actual sizes depend upon the application. They must be the next power of two that is large enough. (If not large enough, the linker will complain.) The alignments must equal the sizes. Now enable loading sys_code into MPU[6] and sys_data into MPU[7] in sb_MPUInit(). Super RegionsThe next step is to define super regions for the SRAM, ROM, and DRAM in the system. These regions serve as temporary replacements for BR. Consult the linker map to determine the starting address and how much memory is being used in each memory area. Then pick the next larger power of two for the region size. The following template is an example: MPA const mpa_tmplt_app =
{
/*0*/ {0x20000000 | V | S0, PRW_DATA | N7 | (0x10 << 1) | EN}, /* SRAM in use */
/*1*/ {0x00200000 | V | S1, PCODE | N7 | (0x11 << 1) | EN}, /* ROM in use */
/*2*/ {0xC0000000 | V | S2, PRW_DATA | (0x14 << 1) | EN}, /* RAM in use */
/*3*/ {0x40011000 | V | S3, PIO | (0x9 << 1) | EN}, /* USART1 */
/*4*/ { 0 | V | S4, 0} /* empty */
};
This template is loaded into the Memory Protection Array (MPA) for every task, so the tasks will run without BR. If a task gets a Memory Manage Fault (MMF), then it needs access to something outside of all regions. This can be fixed by enlarging regions, adding a new region in slot 4, or in the worst case, not loading a template into its MPA, thus leaving the task operating in BR. Such a task can be fixed later, possibly by dividing it into smaller tasks. A significant gain has been made at this point: handlers and ISRs are running, as they were before, but all or most tasks are running in reduced memory regions with strictly controlled attributes (e.g. RO, XN, etc.) This is likely to reveal latent errors. In addition, significant spare memory, if present, has been protected from access by wild pointers and malware,. Task-Specific RegionsThe next step is to identify the most untrusted or vulnerable task or group of tasks to isolate from the rest of the system. This might be a networking subsystem or third-party code. For simplicity, we will deal with a single task, taskA, here. The first step is to group code and data into task-specific regions and to define blocks in the linker command file to hold these regions. The linker can pull together parts of regions from different modules so that code and data reorganization is not necessary, though perhaps desirable. It is convenient to name a task's regions after the task, e.g.: taskA_code and taskA_data. Next, define common code and data regions to hold RTOS and other system services and to hold common data needed by them. These might be named pcom_code and pcom_data, respectively. At this point, taskA is a ptask, so pcom_code needs to include the actual code for the RTOS and other system services that is needed by taskA, and pcom_data needs to include data needed for these services. Then, create mpu_tmplt_taskA and modify the code to load it into the MPA for taskA, instead of mpa_tmplt_app. taskA is now partially isolated from all other tasks. Will it run? This is where the tire meets the road. Memory Manage Faults (MMFs) from taskA are likely to occur due to references outside of its regions or due to attribute violations (e.g. writing to ROM.). These require good debugger or trace tools to find easily. umode OperationThe final step, is to make taskA a utask. This is done by setting its umode flag. Now when it is dispatched, PendSV_Handler() will set CONTROL = 0x3, which causes the processor to run in unprivileged thread mode using the task's stack. In addition, add #include xapiu.h ahead of the task's code. This forces the SWI API to be used for RTOS service calls and other system service calls rather than direct calls, as in pmode. At this point, it is probably desirable to pull all of taskA's code together into a single module since xapiu.h applies to all code that follows the point where it is included. (I draw a barbed wire barrier ahead of this point to remind me that the code above runs in pmode and the code after runs in umode.) Before actually running taskA, replace its pcom regions with ucom_code and ucom_data. The first contains the system service shells that implement SWI system services thus protecting them and their data from taskA. When taskA first starts running as a utask, PRIVILEGE VIOLATION errors are likely, indicating that restricted service calls are being made. These are calls that should not be made from utasks, such as TaskStop(), PowerDown(), etc. This necessitates recoding to not use those services. One approach is to split taskA into a ptask, which directly calls these services (e.g. TaskCreate()) and a utask, which does not. Alternatively, taskA could start as a ptask, make all of the restricted service calls that it needs (e.g. SemCreate()), then restart itself as a utask. (It must restart itself so that the PendSV_Handler() will change CONTROL to 0x3.) Once you get taskA running as a utask, you have a task which cannot harm critical system resources. It can only access its own code, data, and stack, plus common code and common data shared with other utasks in its subsystem. ConclusionIf all has gone well, untrusted code is running in utasks, trusted code is running in ptasks, and you and your boss can sleep well again. Critical parts of the system are strongly isolated from utasks. Though ptasks provide less security than utasks, they are convenient stepping stones to utasks and they provide increased protection for software that must run in privileged mode. It will probably take a fair bit of work to achieve the necessary changes. The important aspect of the above procedure is that it lays out a logical process for this work and after each step, the system can be tested and if it is not running properly, problems can be traced and fixed. You will not be confronted with an unmanageable number of problems all at once. Small steps will lead to wonderful outcomes. This procedure naturally leads to a succession of security releases, each making your system less vulnerable to hacking and dealing with vulnerabilities in order of importance. An additional benefit of MPU conversion is a more reliable system due to finding latent bugs as the conversion proceeds and providing greater protection against environmental events such as energetic particles and voltage spikes. For more information, see www.smxrtos.com/mpu. Ralph Moore |
||||||||||||||||
| An Insecure Router | ||||||||||||||||
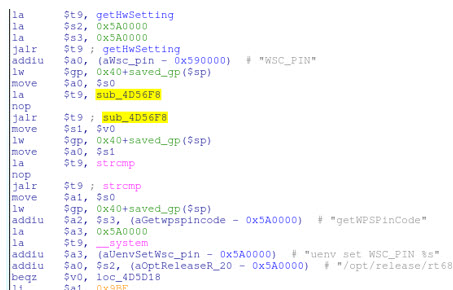
You can't open a newspaper without reading about a computer breech today. We embedded people have a lot of problems we address daily, but security is one too few consider. There's little obvious upside to the boss when asked to spend development dollars to harden a product; the benefits become blindingly clear only after a system is compromised. It's not often we get to see the meaty details about an insecure device. Craig Heffner, Embedded Engineer at Tactical Network Solutions has a nice writeup about uncovering a security problem which I'm using by permission: In an effort to produce more secure devices, developers and development teams tend to put a heavy emphasis on secure coding standards, avoiding inherently unsafe functions, and the use of code profiling tools. But the reality is that even the best written code can pose a security risk if the human-dictated logic behind it is flawed. A good example of this is the D-Link DIR-810L wireless router, which allows any unauthorized individual to wirelessly retrieve the WiFi network encryption key in a matter of seconds! This is a serious security flaw that does not stem from any specific coding vulnerabilities, but rather from flaws in the programmer's logic. To understand this bug it is necessary to understand the two technologies behind it: WPA WiFi encryption and WPS (WiFi Protected Setup). WPA is the de-facto standard for WiFi encryption, and while it has proven itself to be reasonably robust, brute force attacks against the WPA pre-shared key (more commonly referred to as the "WiFi password") are still possible. Although the WiFi password can be made reasonably long and complex, most end users can't remember long, complex passwords, so they choose shorter, more predictable passwords, which in turn are easier to brute force. To address this problem, the WiFi Alliance developed the WPS protocol, which provides a mechanism for WiFi access points to distribute the WPA pre-shared key to authorized devices. This way, humans don't need to ever remember the key, and it can be made very long and complex. The details of how WPS works is outside the scope of this article, and there are actually several different mechanisms through which WPA keys may be distributed to authorized devices. What is important to know is that every SOHO WiFi router has an 8 digit WPS pin assigned to it at the factory, and the WiFi router will give literally anyone your WiFi password provided that they can prove knowledge of this 8 digit pin. Suffice to say, keeping this pin number a secret from unauthorized individuals is paramount for your network's security! This raises an interesting question for attackers: can this 8 digit pin be easily guessed, or even better, derived from some predictable data (note that most brute force attacks against WPS have been largely mitigated for several years now)? The answer for the DIR-810L - as well as many other D-Link WiFi routers - is yes. The relevant code for mounting an attack against WPS lies in the DIR-810L's ncc binary, which is a Linux application running on the router that provides back-end services for many other processes and services, including the HTTP and UPnP servers. Disassembling the ncc binary in the IDA Pro disassembler, we find several string references to WPS inside a function named getWPSPinCode:
Even if you aren't familiar with MIPS assembly, it should be apparent that this snippet of code has something to do with the WPS pin. But, the WPS pin itself is actually retrieved by another subroutine, sub_4D56F8. Since the WPS pin is typically programmed into NVRAM at the factory, one might expect sub_4D56F8 to simply be performing some NVRAM queries, but that is not the case, as can be seen here:
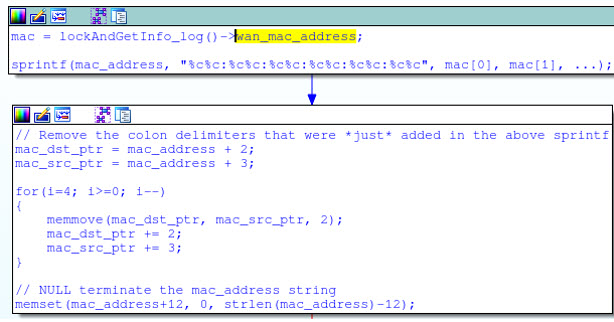
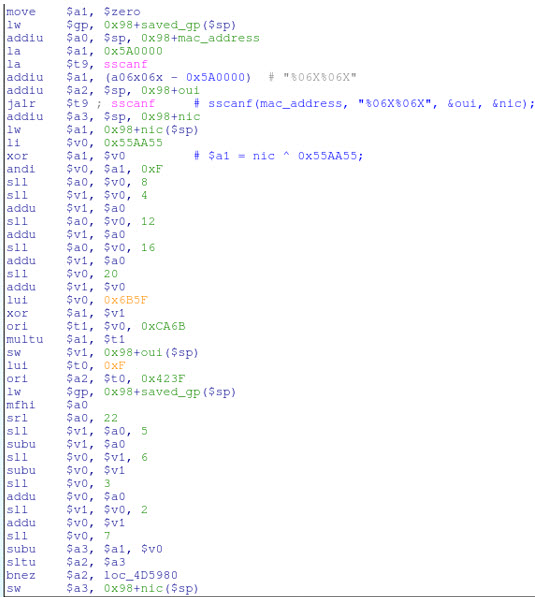
I've manually converted the first few blocks of assembly in IDA Pro into pseudo-C code and added some comments for better readability. It should be clear that the MAC address of the router's WAN interface is being used by this function, which suggests that the MAC address may be used to derive the WPS pin. This is bad because MAC addresses are not encrypted over WiFi! What's more, MAC addresses are assigned sequentially by manufacturers, so the WiFi MAC address (aka, the BSSID) is typically only off-by-one from the WAN MAC address. This means that any unauthorized wireless user can passively capture the WiFi MAC address, and easily predict the WAN MAC address. But is the WPS pin in fact derived from the WAN MAC address? And if so, how? Well, that requires us to delve further into the sub_4D56F8 function's disassembly, which is rife with multiplications, xor's, and bit shifting:
While the math being performed is not complicated, determining the original programmer's intent is not necessarily straightforward due to the assembly generated by the compiler. Take the following instruction sequence for example: li $v0, 0x38E38E39
multu $a3, $v0
mfhi $v0
srl $v0, 1
Directly converted into C, this reads: v0 = ((a3 * 0x38E38E39) >> 32) >> 1; Which is just a fancy way of dividing by 9: v0 = a3 / 9; Likewise, most multiplication and modulus operations are also performed by various sequences of shifts, additions, and subtractions. This tedium is the plight of the reverse engineer, but its rewards are well worth the effort. After translating the entire sub_4D56F8 disassembly listing into a more palatable format, it's obvious that this code is using a simple algorithm to generate the default WPS pin entirely from the NIC portion of the device's WAN MAC address:
unsigned int generate_default_pin(char *buf)
{
char *mac;
char mac_address[32] = { 0 };
unsigned int oui, nic, pin;
/* Get a pointer to the WAN MAC address */
mac = lockAndGetInfo_log()->wan_mac_address;
/*
* Create a local, NULL-terminated copy of the WAN MAC (simplified from
* the original code's sprintf/memmove loop).
*/
sprintf(mac_address, "%c%c%c%c%c%c%c%c%c%c%c%c", mac[0],
mac[1],
mac[2],
mac[3],
mac[4],
mac[5],
mac[6],
mac[7],
mac[8],
mac[9],
mac[10],
mac[11]);
/*
* Convert the OUI and NIC portions of the MAC address to integer values.
* OUI is unused, just need the NIC.
*/
sscanf(mac_address, "%06X%06X", &oui, &nic);
/* Do some XOR munging of the NIC. */
pin = (nic ^ 0x55AA55);
pin = pin ^ (((pin & 0x0F) << 4) +
((pin & 0x0F) << 8) +
((pin & 0x0F) << 12) +
((pin & 0x0F) << 16) +
((pin & 0x0F) << 20));
/*
* The largest possible remainder for any value divided by 10,000,000
* is 9,999,999 (7 digits). The smallest possible remainder is, obviously, 0.
*/
pin = pin % 10000000;
/* The pin needs to be at least 7 digits long */
if(pin < 1000000)
{
/*
* The largest possible remainder for any value divided by 9 is
* 8; hence this adds at most 9,000,000 to the pin value, and at
* least 1,000,000. This guarantees that the pin will be 7 digits
* long, and also means that it won't start with a 0.
*/
pin += ((pin % 9) * 1000000) + 1000000;
}
/*
* The final 8 digit pin is the 7 digit value just computed, plus a
* checksum digit. Note that in the disassembly, the wps_pin_checksum
* function is inlined (it's just the standard WPS checksum implementation).
*/
pin = ((pin * 10) + wps_pin_checksum(pin));
sprintf(buf, "%08d", pin);
return pin;
}
Since the BSSID is only off-by-one from the WAN MAC, an unauthorized attacker can easily retrieve the WPA key of any DIR-810L's access point by: Passively capturing a WiFi beacon packet, which will contain the BSSID
There are a variety of readily available, open source tools to perform packet captures and send WPS requests, all of which are part of any standard "hacker toolkit". But the DIR-810L isn't the only device to use this algorithm. In fact, it has been confirmed in no fewer than 22 different D-Link router models, dating all the way back to 2007 when WPS was first publicly introduced. The sad reality is that the secure solution to this would have been considerably simpler: just generate a pseudo random WPS pin for each device! The rand() function is not difficult to use. There should be no reason to use predictable input data to generate pins or passwords of this nature. To some, I'm sure this example will seem like an obvious failure on the part of D-Link's development team. But stop and think for a moment about how many different protocols and interdependent technologies are being constantly pushed into new products, particularly networked and IoT devices. How many of your developers are familiar with WPS? How many know how WPA works, and what gets encrypted and what doesn't? How many know how MAC addresses are assigned at the factory? And how many people in your development team are concerned about any of that in their push to get a product to market? |
||||||||||||||||
| Jobs! | ||||||||||||||||
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intent of this newsletter. Please keep it to 100 words. There is no charge for a job ad. The NY Times has an interesting article (sorry - it may be paywalled) about how to hire an employee; smart people looking for work might get some good ideas about how to approach an interview. |
||||||||||||||||
| Joke For The Week | ||||||||||||||||
Note: These jokes are archived at www.ganssle.com/jokes.htm. If Dr. Seuss Were a Technical Writer: If your cursor finds a menu item followed by a dash, You can't say this? What a shame sir! We'll find you Another game sir. If the label on the cable on the table at your house, When the copy of your floppy's getting sloppy on the disk, |
||||||||||||||||
| Advertise With Us | ||||||||||||||||
Advertise in The Embedded Muse! Over 27,000 embedded developers get this twice-monthly publication. . |
||||||||||||||||
| About The Embedded Muse | ||||||||||||||||
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. |