|
You may redistribute this newsletter for non-commercial purposes. For commercial use contact jack@ganssle.com. |
| Contents |
|
| Editor's Notes |

Did you know it IS possible to create accurate schedules? Or that most projects consume 50% of the development time in debug and test, and that it's not hard to slash that number drastically? Or that we know how to manage the quantitative relationship between complexity and bugs? Learn this and far more at my Better Firmware Faster class, presented at your facility. See https://www.ganssle.com/onsite.htm for more details.
Want to win $25,000? The Federal Trade Commission is running their "IoT Home Inspector Challenge" contest. Design a "a technical solution ("tool") that consumers can use to guard against security vulnerabilities in software found on the Internet of Things (IoT) devices in their homes." More info here.
If you are experienced in the ways of embedded design, please participate in this quick online survey. It should only take 5 minutes, and afterwards, you'll be automatically entered into a drawing to win one of two USB logic analyzers or one of three Amazon gift cards.
|
| Quotes and Thoughts |
"A bad engineer tries to get something to work. A good engineer tries to get something not to work -- that is, after getting it working, the good engineer tries to find its limits and make sure they are well-understood and acceptable." - Michael Covington |
| Tools and Tips |
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past.
Rowan Gifford sent a link for the IoT Security Foundation:
|
The IoT Security Foundation (https://iotsecurityfoundation.org/) is doing good work trying to create a standard for embedded security. They've just released a best practise guide and a standard best practise mark, I believe they are working towards a formal testing and accreditation process also. |
In the last issue Doug Gibbs suggested that one idea to secure the IoT was certification. Justin Shriver wrote to note that organizations exist to certify devices, and cited Wurldtech and ISASecure. |
| Freebies and Discounts |
This month's giveaway is a Silicon Labs Thunderboard Sense. It's billed as "feature packed development platform for battery operated IoT applications. The mobile app enables a quick proof of concept of cloud connected sensors. The multi-protocol radio combined with a broad selection of on-board sensors, make the Thunderboard Sense an excellent platform to develop and prototype a wide range of battery powered IoT applications." I bought it hoping to play with the thing but just don't have the time.
Enter via this link. |
| We Need Simpler Ways to Access I/O on MCUs |
Jon Titus, truly one of the pioneers of the microprocessor era, sent in the following:
|
Between the holidays I started to work with a Texas Instruments LaunchPad; a small board with a USB connection, two pushbuttons, an RGB LED, and many open I/O pins. I bought a couple of these boards because they looked like fun to work with. They're not. The hardware looks fine, but code-creation tools haven't kept pace with newer, complicated semiconductors.
The board's processor chip--a Tiva-family TM4C123GH6PM--provides an ARM Cortex-M4F core, and Texas Instruments offers a free IDE, Code Composer Studio (CCS). I had used CCS many years ago with another family of MCU chips, so it didn't take long to set up the latest version. To ensure the LaunchPad board had a good connection with my lab PC I looked for a simple example--the usual LED-blink code. I found one that would control an LED based on a pushbutton's state. It required 62 lines of code. Here's about half the code, which requires many GPIO setup functions:
// Input and output variables
uint8_t In = 0;
uint8_t Out = 0;
// Initialize PLL to 80MHz
Init_PLL(4);
// GPIO Initialization
SYSCTL_RCGCGPIO_R |= 0x00000020; // Activate clock for Port F
__asm("nop; nop; nop;"); // Three clock cycle delay for
// clock to start
GPIO_PORTF_LOCK_R = GPIO_LOCK_KEY; // Unlock GPIO Port F
GPIO_PORTF_CR_R = 0x01; // Allow changes to PF0
GPIO_PORTF_DIR_R = 0x0E; // PF4,0 in | PF3-1 out
GPIO_PORTF_PUR_R = 0x11; // Enable pull-up on switches
GPIO_PORTF_DEN_R = 0x1F; // Enable digital IO on PF4-0
// Main While Loop
while(1)
{
In = GPIO_PORTF_DATA_R & 0x10; // Read Sw1
In >>= 2;
Out = GPIO_PORTF_DATA_R;
Out = Out & 0xFB;
GPIO_PORTF_DATA_R = Out | In;
}
TI has created a complicated I/O-port structure that provides almost every conceivable operation and type of interrupt. With all this complexity I'd hoped the new version of CCS would include a tool to simplify setup and use of I/O ports. In my case, an input pin and an output pin. TI supplies a free tool called PinMux that lets programmers select how they want internal peripherals to connect to I/O pins, and how the I/O pins get used. To test PinMux I selected two pins on Port A for a UART and got four lines of code, two for the UART transmitter and two for the receiver. Big help. I could have figured this out on my own.
MAP_GPIOPinConfigure(GPIO_PA0_U0RX);
MAP_GPIOPinTypeUART(GPIO_PARTA_BASE, GPIO_PIN_0);
and
MAP_GPIOPinConfigure(GPIO_PA1_U0TX);
MAP_GPIOPinTypeUART(GPIO_PARTA_BASE, GPIO_PIN_1);
The manual for TI's TivaWare, a library of peripheral functions, runs to 704 pages and devotes 25 pages to descriptions of the 47 UART functions. The example at the section end illustrates only basic UART functions without mention of interrupts, FIFOs, and so on. To learn more I must go through all the UART APIs to determine which ones I need and how to use them.
Why can't tool suppliers assist programmers with setup of basic peripheral and port operations and their initialization and use? Today I'd expect a company to provide an interactive matrix of choices that let me check boxes of the features I need, and enter text as needed, and then give me a block of code to drop into my program. Here's a portion of the type of front-end selection and data-entry window code-tool and MCU suppliers should provide:
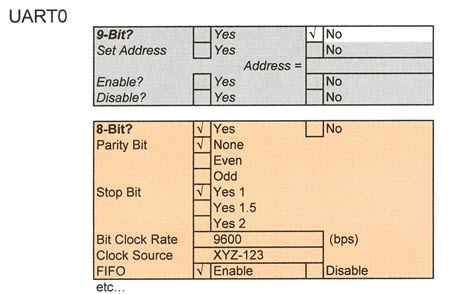
The gray area indicates an operation of function not used. Someone could write the tool program in Visual Basic. Programmers shouldn't have to waste a day figuring out how to setup a UART or other on-chip peripherals. There must be a better way than having to wade through hundreds of pages of datasheets and API descriptions before people can do basic MCU operations. I used TI's product only as examples. Most other development tools provided by MCU manufacturers suffer from similar problems. |
Jon's point is excellent. Modern microprocessors are getting very complex. But some vendors do have some interesting solutions, like mbed and Imagecraft. |
| while(1)printf("Comments On"); |
Muses 319 and 320 provoked a lot of interesting discussion about commenting practices.
James Fowkes wrote:
|
One suggestion I have for commenting code - where possible, moved a line or group of lines to a separate function. Then the purpose of the line or block is documented in the function name itself. To apply that to your code snippet,
a= out_pr * scale;
becomes
a = scale(out_pr)
where scale is the new function.
Then we give it a better name that actually represents the purpose:
a = apply_pd_scaling_factor(out_pr);
This is, I think, much closer to "self documenting" code. Care must be taken to ensure that performance is not affected and stacks are not blown etc. Also in some cases the compiler inlining the functions (or not) may be an issue.
This technique tends to create smaller, easier to understand, more composable functions and I've found that it can also reduce the amount of global variables. It can also aid processes like TDD. You can treat it like a refactoring process.
Finally, I have no data to support all this. It just works for me. |
John Taylor shared:
|
Self documented code? I comment my code A LOT and often encounter the best example of how ridiculous is the concept of code that is so obviousness that comments are unnecessary.
I often write drivers and communication protocols for new devices and systems and then pass my code off to the firmware guys so that they have a known working baseline on which to build. As I test my code I try to detail every single step; not just to remind myself later but to instruct others right now.
No matter how carefully I describe the steps, there are ALWAYS holes that I have to patch when the recipient starts to use my code and doesn't quite understand what I am doing. The reason is very simple: When you get good at driving you can go a hundred miles without remembering this turn or that. Just the same way I can make coding choices that are practiced and obvious for me but mysterious to another, or mysterious to me given enough time. It's a problem that gets worse the better you get at coding.
Assume you are writing comments for an intern because that may very well represent the skill level of the next person to work on your code, or your skill level for this piece of code a year from now. |
Duncan Peterson had a humorous twist on self-documenting code:
|
I am 72, retired and wrote code in the 70's and 80's because I had to. There was no one else to do it. And I have written self documenting code - and lived to understand how incredibly stupid it is. As a result of years of software / firmware and hardware design and maintenance, I now know self documenting code is self documenting. It is documenting who needs to be told it is company policy, as I believe it is everywhere that counts, or they will be replaced. Their code should be randomly examined and if they don't comply they should be replaced before they can do more harm. |
Do you have metrics on how many comments are needed? Larry Rachman does:
|
Re: comments, I try to do my best, however this can be pretty subjective. But when other engineers started making fun of my having too many comments, I knew I was on the right track. |
Steve Jahr wrote:
|
I have struggled for years to come up with a way to accurately describe what/how to comment to Jr Engineers.
I used to have one rule: to capture the "AHA!" information. These were the insights you would suddenly get after working with a piece of code for 3-6 months.
I recently added another rule though: to capture the "WTF?!" information. These are the insights to why you did it *this* way and not *that* way when one might wonder otherwise. |
Hendrik Lipka prefers extracted methods:
|
Yes, I write comments in my code, but I prefer not to need this. Since the code I produce is used by other engineers, I document the public API, and QA surely looks that I do this properly.
Regarding inline/block comment, there is an interesting heuristic:"replace comments with extract method"
This code surely needs comments, since it cannot be properly understood without them:
a= out_pr * scale; // scale the input using the calibrated coefficient
if(Mark2) // mark2 board components mean there is a
a= a+offset; // -2.6mVolt offset which must be corrected for.
But what if I write it this way:
a=scaleFromBitsToRealUnits(out_pr);
if(boardNeedsOffsetCorrection())
{
a=a+calculateOffsetForBoardRevision();
}
// *** helper functions
// scaling can be done as simple multiplication with a constant factor
// there is no offset involved
float scaleFromBitsToRealUnits(float input) {
return input*scale;
}
// some board revisions have a bug, so they need offset correction
bool boardNeedsOffsetCorrection() {
return mark2;
}
// mark 2 boards produce a -2.6mV offset // other revisions are good AFAIK
float calculateOffsetForBoardRevision() {
if (mark2)
{
return offset;
}
return 0;
}
The actual code can be read quite easily, no needs for comments.
Actually you can nearly read your code as an English sentence. Comments can be done in the places where its actually needed, and where the additional details are not an overhead.
Yes, the code gets bigger, and not all embedded compilers like this many function calls. But with newer and bigger MCUs it doesn't matter that much any more, and improved development speed counts quite a lot today...
(And surely even my version can be improved upon, esp. with regarding to naming the variables...) |
Steve Paik writes that source control can be an option:
|
I have gone back and forth on the "code is self documenting" vs "comments are necessary" spectrum. As always, one size does not fit all, and different processes are needed at different times.
One thing that hasn't been addressed yet is the role of source control in this mix. Most source control systems have a 'blame' function that allow the developer to track the exact commit that generated the line of code. If the company is diligent about tracking bugs with commit logs, it's possible to get more explanation by doing a little bit of forensics. Obviously not as good as having comments in-line, but perhaps it can help strike a balance between the two camps (comment too little vs too verbose).
I wish I had a better answer for giving people better habits in terms of writing comments, but I don't. But, here's some stream of consciousness that is coming to me now....
- I hate having a rigid policy such as using doxygen, precisely because there are times that code really is self documenting. For instance, when I'm writing a bunch of getter/setter functions for a class, I really don't need to specify the input params (void), return values (the member variable), etc. In cases like these, I'll comment things that are out of the ordinary, and leave the rest of it uncommented.
- I have fallen into the trap of writing tons of comments, only to have my entire program turned up-side-down and having to rewrite the code AND the comments really makes me angry. I suppose this is where up-front design would save some of this pain, but life isn't always ideal. I imagine those that say "code is self documenting" have experienced this too often.
- I have also written comments that only I would understand, i.e. someone with a deep background in analog circuit design, control theory, and DSP, and it isn't fair to others coming afterwards to try to decipher both the comments and the code. It's hard sometimes to pick what level to write at... I've also been a victim of this on the receiving end as well.
Looking at my thoughts, I imagine people are shaped by their experiences. Hence, I like what you have done with your muse above. By telling stories, you are explaining 'why' people feel the way they do, and how that can relate to a new situation. |
|
| Jobs! |
Let me know if you’re hiring embedded
engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intent of this newsletter.
Please keep it to 100 words. There is no charge for a job ad. |
| Joke For The Week |
Note: These jokes are archived at www.ganssle.com/jokes.htm.
You may be an engineer if:
If you have "Dilbert" comics displayed anywhere in your work area
If you carry on a one-hour debate over the expected results of a test that actually takes five minutes to run
If you are convinced you can build a phaser out of your garage door opener and your camera's flash attachment
If you have modified your can opener to be microprocessor driven |
| Advertise With Us |
Advertise in The Embedded Muse! Over 27,000 embedded developers get this twice-monthly publication. . |
| About The Embedded Muse |
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and
contributions to me at jack@ganssle.com.
The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get
better products to market faster.
|



