|
|
||||||||
You may redistribute this newsletter for noncommercial purposes. For commercial use contact jack@ganssle.com. |
||||||||
| Contents | ||||||||
| Editor's Notes | ||||||||
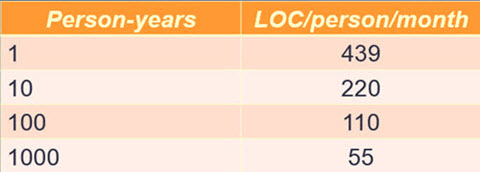
IBM data shows that as projects grow in size, individual programmer productivity goes down. By a lot. This is the worst possible outcome; big projects have more code done less efficiently. Fortunately there are ways to cheat this discouraging fact, which is part of what my one-day Better Firmware Faster seminar is about: giving your team the tools they need to operate at a measurably world-class level, producing code with far fewer bugs in less time. It's fast-paced, fun, and uniquely covers the issues faced by embedded developers. Information here shows how your team can benefit by having this seminar presented at your facility. Better Firmware Faster in Australia and New Zealand: I've done public versions of this class in Europe and India a number of times. Now, for the first time, I'm bringing it to Sydney on November 9 and Auckland on November 16. There's more information here. Seating is limited so sign up early. Better Firmware Faster in Maryland: The Barr Group is sponsoring a public version of this class at their facility on November 2, 2015. There's more information here. |
||||||||
| Quotes and Thoughts | ||||||||
Embedded systems have 20% of the defects of information systems. - Capers Jones. |
||||||||
| Tools and Tips | ||||||||
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past. Andrew Retallack recommends Nuts and Volts magazine. Caron Williams asks of Muse readers:
Amen to this question. I have some ADP172 voltage regulators from Analog Devices here. They're 1 mm square in a WLCSP with four balls. I can barely see the devices, let along solder them! |
||||||||
| Freebies and Discounts | ||||||||
I bought a $50 zero to 10 MHz signal generator from eBay. It's a new unit which was shipped from China; these things are for sale all the time on that site. I did a review of the unit, and it is this month's giveaway. Go here to enter. The contest will close at the end of August, 2015. It's just a matter of filling out your email address. As always, that will be used only for the giveaway, and nothing else.
|
||||||||
| More on In-the-Field Firmware Updates | ||||||||
In the last issue I asked how people go about doing in-the-field firmware updates. Several readers had replies. One who wishes to remain anonymous wrote:
Ray Keefe contributed this:
|
||||||||
| More on Second Sources | ||||||||
In the last issue I wrote about the troubles we often have with parts going end-of-life. Stephen Irons wrote:
Trevor Woerner said:
Larry Rachman had a story about a part change:
Frequent correspondent Harley Burton also has a tale to tell:
|
||||||||
| Jobs! | ||||||||
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intents of this newsletter. Please keep it to 100 words. There is no charge for a job ad.
|
||||||||
| Joke For The Week | ||||||||
Note: These jokes are archived at www.ganssle.com/jokes.htm. From Steve Bresson - an old joke with a new twist: Two engineers were standing at the base of a flagpole, looking at its top. A woman walked by and asked what they were doing. "We're supposed to find the height of this flagpole," said Sven, "but we don't have a ladder." The woman took a wrench from her purse, loosened a couple of bolts, and laid the pole down on the ground. Then she took a tape measure from her pocketbook, took a measurement, announced, "Twenty one feet, six inches," and walked away. One engineer shook his head and laughed, "A lot of good that does us. We ask for the height and she gives us the length!" Both engineers have since quit their engineering jobs and are currently serving as elected members of Congress. |
||||||||
| Advertise With Us | ||||||||
Advertise in The Embedded Muse! Over 23,000 embedded developers get this twice-monthly publication. . |
||||||||
| About The Embedded Muse | ||||||||
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. |