|
|
||||
You may redistribute this newsletter for noncommercial purposes. For commercial use contact jack@ganssle.com. |
||||
| Contents | ||||
| Editor's Notes | ||||
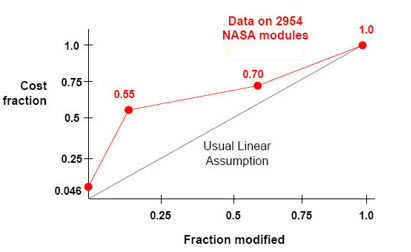
Many of us think there's some sort of more or less inverse linear relationship between the amount of software reused and the cost to create firmware. Turns out, that isn't true. NASA has shown that once you start fiddling with about a quarter or less of the code reuse's benefits start to melt away.That's not to knock reuse; I feel that it's probably our only hope of salvation as programs soar in size. But it does say a lot about how we need to go about reuse to get the benefits it promises. This, and a whole lot more, is part of my Better Firmware Faster seminar. It gives your team the tools they need to operate at a measurably world-class level, producing code with far fewer bugs in less time. It's fast-paced, fun, and uniquely covers the issues faced by embedded developers. Learn how your team can benefit by having this seminar presented at your facility. India update: I will be doing a three day version of this class, open to the public, in Bangalore, India July 15-17. Contact Santosh Iyer for more information. |
||||
| Embedded Video | ||||
Saleae makes a number of USB-connected logic analyzers. Their latest offering has a 500 MHz sample rate, and reads analog channels as well as digital. Here's my video review of it. |
||||
| Quotes and Thoughts | ||||
"In science, there is only physics; all the rest is stamp collecting." -
Physicist Ernest Rutherford, ca. 1900. (Rutherford was awarded the Nobel Prize - in Chemistry!) |
||||
| Tools and Tips | ||||
Please submit clever ideas or thoughts about tools, techniques and resources you love or hate. Here are the tool reviews submitted in the past. Steve Karg had thoughts on hand tool suppliers:
|
||||
| Giveaway Winner, and Logic Pro Giveaway | ||||
We ran a contest last month for a giveaway of a GW Instek GDS-1052-U bench scope. Over 1900 distinct people entered. The lucky winner has been notified, but as of this writing hasn't responded. I hope to hear from him soon. This week's video is a review of Saleae's nifty Logic Pro 8 logic analyzer. This month I'll give that unit to another Embedded Muse subscriber. The giveaway will close at the end of June, 2015. Go here to enter. It's just a matter of filling out your email address. As always, that will be used only for the giveaway, and for nothing else. |
||||
| Multicore in Embedded | ||||
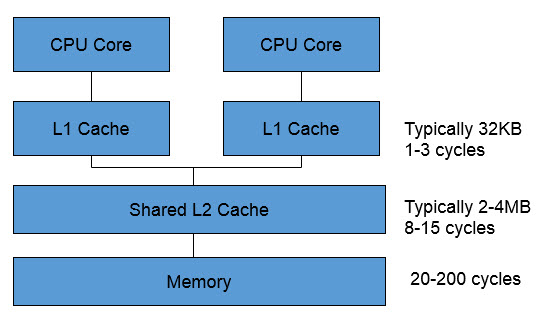
For the past few years the PC and server world has been infatuated with multicore processors. The idea is brilliant: put several, or even many, identical CPU cores on a single chip. A smart OS can partition the workload among the processors, greatly increasing system performance. Transistors are practically free so the incremental cost is low. I use PowerDirector to create videos, and it does a great job using all available system resources. The PC Meter app that shows how much load is on each core goes to 100% on all six in my desktop when rendering video. The fan picks up speed and makes noises I've never heard before. Multicore is making its way into the embedded world, too. Sometimes naively. There's an expectation that doubling the number of compute units, or cores, doubles performance. That may be true in some specialized areas. But the world "multicore" generally refers to symmetric multiprocessing, where two or more identical cores share the same memory. They may even share the L2 cache. This is a typical arrangement:
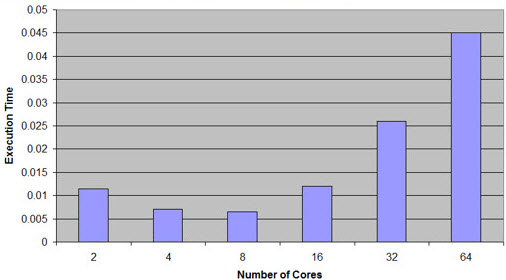
Note that the L1 cache is tiny. Even most 8 bit CPUs can address more memory. As soon as there's a cache miss a call goes to L2 or even main memory. That instruction stalls; if the other core then needs to go outside its L1, there's a conflict. Consider the stalls when going to main memory, which may need dozens (or more) cycles. Sandia National Labs has studied this, for the sorts of compute problems they encounter. They've found that it's not unusual for these memory conflicts to cause a drop in performance as cores are added. Here's some of their data:
Note that there are "embarrassingly parallel" problems that really do benefit from the use of multicore. Those are not often found in the embedded space. Alternatives exist. With asymmetric multiprocessing each core (and these may not be identical CPUs) has its own memory. Atmel's ATSAM4CP parts have a pair of Cortex-M4 processors (one with floating point) that do share memory. However, each core has a bit of memory from which it can run without conflicts, at zero wait states. As always, read the datasheets with care and apply careful engineering judgment. And beware of hype! |
||||
| On Stacks | ||||
Intel's 4004, the first microprocessor, had an on-chip hardware stack a mere three levels deep. When a year later the 8008 came out, it, also had a hardware stack, boosted to a depth of seven words. Since neither had push and pop instructions the stack contained only return addresses from CALL instructions. No, interrupts did not necessarily eat stack space. An interrupt cycle initiated a nearly-normal fetch. It was up to external hardware to jam an instruction onto the bus. Though most designers jammed an RST, a single-byte CALL, more than a few used alternatives like JMP. With these tiny stacks developers constantly worried about deep call trees, for there were no tools to trace program execution. But programs were small. After getting burned once one learned to sketch simple execution path diagrams to track call depth. Even today we have only the most limited ways to troubleshoot a blown stack. Now of course every processor has constantly-used PUSH instructions. Million line programs with explosive numbers of automatic variables and intricate inheritance schemes chew through stack space while masking the all of the important usage details. Add nested interrupt processing asynchronously and unpredictably using even more, and we're faced with a huge unknown: how big should the stack or stacks be? Most developers use the scientific method to compute anticipated stack requirements. We take a wild guess. Get it wrong and you're either wasting expensive RAM or inserting a deadly bug that might not surface for years when the perfect storm of interrupts and deep programmatic stack usage coincide. I've read more than a few academic papers outlining alternative approaches that typically analyze the compiler's assembly listings. But without complete knowledge of the runtime library's requirements, and that of other bits of add-in software like communications packages, these ideas collapse. Today wise developers monitor stack consumption using a variety of methods, like filling a newly-allocated stack with a pattern (I like 0xDEAD) and keeping an eye on how much of that gets overwritten. Some RTOSes include provisions to log high-water marks. But these are all ultimately reactive. We take a stack-size guess and then start debugging. When something goes wrong, change the source code to increase the stack's size. It violates my sense of elegance, paralleling as it does the futile notion of testing quality into a product. It's better to insert correctness from the outset. This article is worth reading, and offers some useful advice. How do you predict stack size? Do you do anything to monitor it during execution? |
||||
| Jobs! | ||||
Let me know if you’re hiring embedded
engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intents of this newsletter.
Please keep it to 100 words. There is no charge for a job ad. |
||||
| Joke For The Week | ||||
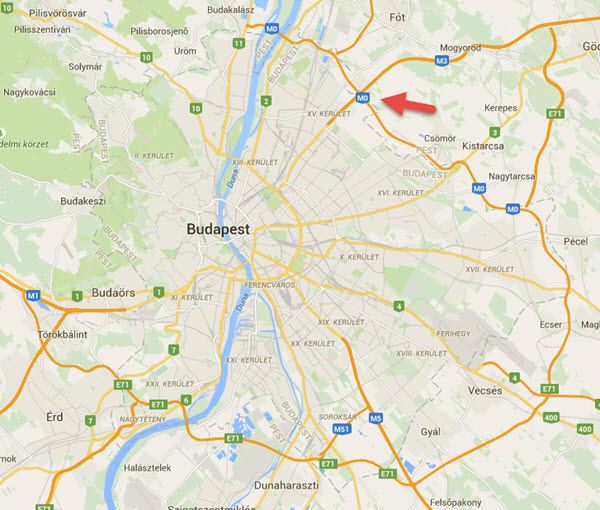
Note: These jokes are archived at www.ganssle.com/jokes.htm. Carrying on the notion of highway engineers counting from zero (just like us) Tamas Stolmar sent this: Actually we have a Highway "0" in Hungary. It runs around Budapest:
Hungary is a small country, and most of our primary roads are running from the capital Budapest, which is located quite in the centre. Of course, it is not finished yet, about two third is yet to be done. The remaining floats somewhere between the dreaming and planning phase, because the missing part should run thru forests, wildlife reservation areas and beautiful hills. It might require long tunnels too, and it is quite expensive. |
||||
| Advertise With Us | ||||
Advertise in The Embedded Muse! Over 23,000 embedded developers get this twice-monthly publication. . |
||||
| About The Embedded Muse | ||||
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. |