|
|
||||
You may redistribute this newsletter for noncommercial purposes. For commercial use contact jack@ganssle.com. To subscribe or unsubscribe go to https://www.ganssle.com/tem-subunsub.html or drop Jack an email. |
||||
| Contents | ||||
| Editor's Notes | ||||
Did you know it IS possible to create accurate schedules? Or that most projects consume 50% of the development time in debug and test, and that it’s not hard to slash that number drastically? Or that we know how to manage the quantitative relationship between complexity and bugs? Learn this and far more at my Better Firmware Faster class, presented at your facility. See https://www.ganssle.com/onsite.htm. John Regehr's blog "Embedded in Academia" often has insightful posts. The latest is about the use of assertions, and is highly recommended. |
||||
| Quotes and Thoughts | ||||
"It is easier to write a new code than to understand an old one." John von Neumann, 1952. (Johnnie, as he was called, was fascinating. For more on this amazing man I recommend Turing's Cathedral, by George Dyson, and John von Neumann, by Norman Macrae.) |
||||
| Tools and Tips | ||||
Please submit neat ideas or thoughts about tools, techniques and resources you love or hate. Darcio Prestes wrote:
|
A Twist on Filtering | |||
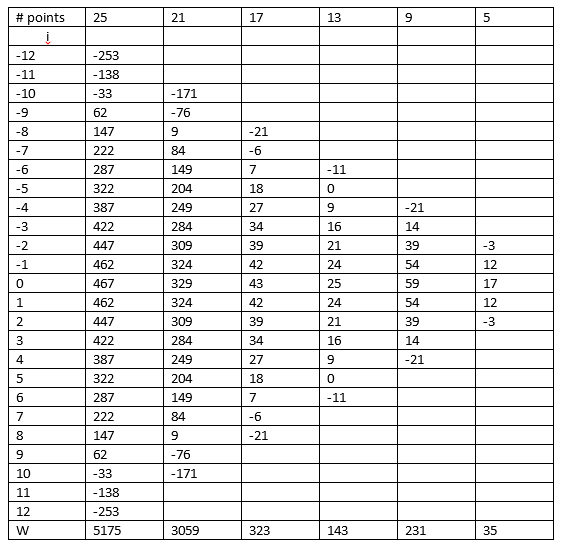
Our firmware often reads real-world data, commonly from an A/D converter. Noise is expected, and there are a lot of strategies to extract useful information from the mess of raw data. It's common to apply an average, which reduces noise at a rate proportional to the square root of the number of samples in the average. Since any system will eventually be bound by computer and A/D speed, this results in a sort of diminishing return. A tradeoff must be made between system response time and allowable noise level. An average is a special case of the finite impulse response filter (FIR filter), which samples the N most recent data points, multiplying each point by some number, summing them, and then dividing by the appropriate factor. When averaging, each point is multiplied by 1, so every bit of data has an equal effect on the result. Often that's undesired; sometimes older data, for instance, should contribute less than the most recent acquisition. Averaging also smears the peaks. By tailoring the multiplication coefficients one can make filters that are responsive and less likely to distort the data. Suppose we're reading a continuous stream of data and wish to smooth it over 5 points. The math looks like: Result=(C0*Di-4 + C1*Di-3 + C2*Di-2 + C3*Di-1 + C4*Di)/W C0, C1, C2, C3, and C4 are weighting coefficients. For a simple average they're one. D are the data points, and W is a weighting factor, which is the number of data points when doing an average. This generates an output for each point at time i that is the average of all the points in the vicinity of i. In effect, for each i we make an output by multiplying the input waveform by a unit step function, and summing the results at each point. The unit step is then slid one point to the right and the algorithm repeated. Adjusting the number of points included in each average simply changes the width of the step. Wider steps (i.e., a bigger N) give more noise-free data, but at the price of smearing it. Narrow steps give noisy signals that are more faithful to the input data. A step exactly one point wide gives the unmodified input signal. In averaging we slide a very simple function along the axis. Its coefficients are 0,0,0,0,0,0,0,1,1,1,1,1,0,0,0,0. Each string of zeroes is infinitely long, and the string of ones is N points wide. Why not convolve the input data with a function that resembles the signal itself? In other words, pick a set of weights that accentuate the mid-point and include reduced levels of the more distant points. Computationally this involves multiplying each point in the vicinity of i with a weighting factor, and then averaging the results. Points far away from the center play a much less significant role in the result, giving a more faithful output waveform. In other words, use a set of weighting values to fit the result to the anticipated result. Any continuous function can be approximated with a polynomial. One can take advantage of this and represent the signal's shape over a small interval with a polynomial of some degree. Then, fit a curve through the data to generate a more realistic model of the signal we're digitizing. One approach is a least squares fit, which minimizes the sum-squares error; that is, the square root of the sum of the squares of the error at each point is a minimum. The error at each point is the difference between what the fitted curve predicts and the actual data. It's usually difficult to compute a least squares polynomial in real time. It turns out that one can use the FIR filter approach to quickly do the work. I'll present the coefficients, but interested readers should check out the seminal paper by Abraham Savitzky and Marcel Golay in the July, 1964 issue of Analytical Chemistry (Volume 36 Number 8). Suffice to say that a set of integers can be defined that, when convolved with an input signal, gives an output waveform that is a least squares fit to an ideal signal over a narrow range. Here are a few sets of integers that define convolving functions that will yield least squares fits to input data. Different convolution intervals are given. A polynomial fit will be made over the number of sample points shown; that is, the column labeled "25" fits 25 data points, that labeled "5" fits 5. The first row is the index into the coefficients. The row labeled "W" is the weighting factor.
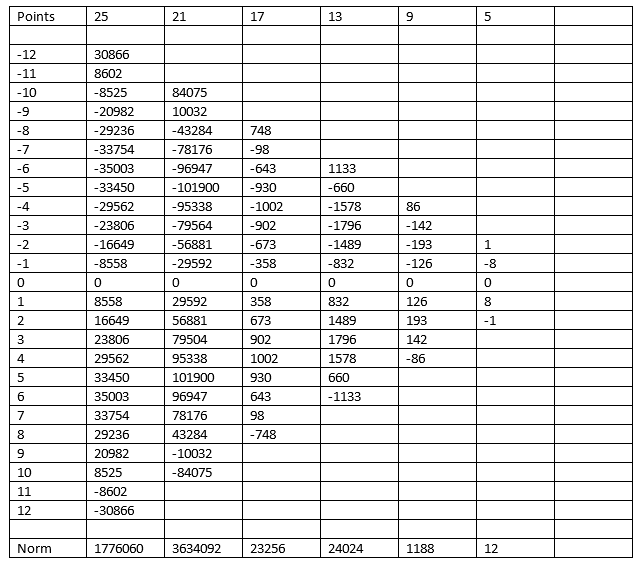
For instance, to use the set of 5 integers, compute: (-3*Di-2 + 12*Di-1 + 17*Di + 12*Di+1 + -3*Di+2)/35 If the data is very busy (i.e., over only a few sample points it undergoes a lot of maxima and minima), then a small set of integers should be picked (e.g., 9 rather than 21). After all, the method attempts to fit a curve to a short segment of the input data; busy data is all but impossible to fit under any circumstances. Data that changes slowly can use the larger sets of integers, resulting in more smoothing. But it gets better. Suppose you need to compute the rate of change of some data. Remember circuit theory? (If you don't just skip this equation.) Those who managed to stay awake may recall that the convolution integral has an important property, namely: f'(t)=g(t)*h'(t) and, f'(t)=g'(t)*h(t) where * represents the convolution process and the prime marks indicate the derivative. This means if you need to both smooth and differentiate a signal, you can convolve the signal with the derivative of the convolving function. You never need to explicitly differentiate the input signal. So, if we compute the derivative of the least squares function, we can generate a new set of integers that both smooth's and differentiates the data. Again, refer to the cited paper for details. Theoretically, you can extend this concept to any number of derivatives, though above about the third derivative the integers get unwieldy. The following set of integers computes the first derivative:
Apply these in exactly the same manner as previously described. A lot of us primarily use old-fashioned averaging for noise reduction, often simply summing successive sweeps together. The convolution is a different way of looking at noise reduction, potentially improving response time by performing a smart average over the time dimension. It even lets you differentiate the signal, for essentially no cost in speed or memory. Of course, any sort of averaging does smear the data somewhat, but in smoothing, as in life, everything is a compromise. |
||||
| Is a Degree Necessary? | ||||
In my experience some engineers are plodders. They just don't get it. Sure, they can crank some C or design a bit of logic but their creations are leaden, devoid of style, crude, slow and just not elegant. Then there are the superstars, those few who establish a mind-meld with the code or electronics. When the system doesn't work and mysterious bugs baffle all of our efforts, the guru licks his finger and touches a node and immediately discovers the problem. We feel like idiots; he struts off in glory. Sort of like Bruno in last issue's Elvis story. Who are these people, anyway? An astonishing number of them have unusual academic credentials. Take my friend Don. He went off to college at age 18, for the first time leaving his West Virginia home behind. A scholarship program lined his pockets with cash, enough to pay for tuition, room, and board for a full year. Cash - not a safer University credit of some sort. A semester later he was out, expelled for non-payment of all fees and total academic failure, with an Animal House GPA of exactly 0.0. The cash funded parties; the late nights interfered with classes. His one chance at a sheepskin collapsed, doomed by the teenage immaturity that all of us muddle through with varying degrees of success. Today he's a successful engineer. He managed to apprentice himself to a startup, and then to parley that job into others where his skills showed through, where enlightened bosses valued his design flair despite the handicap of no degree. Then there's my dad who breezed through MIT on a full scholarship. Graduating with a feeling that his prestigious degree made special he started at Grumman in 1950 as a mechanical engineer working on aircraft. To his shock the company put him on the production line for six months, riveting airplanes together. This outfit put all new engineers in production to teach them the difference between theory and practicality. He came out of it with a new appreciation for what works, and for the problems associated with manufacturing. What an enlightened way to introduce new graduates to the harsh realities of the physical world! A grizzled old machinist, hearing of my engineering desires while I was in high school, took me aside and warned me never to be like "those" engineers who designed stuff that couldn't be built. Experience is a critical part of the engineering education, one that's pretty much impossible to impart in the environment of a university. You really don't know much about programming till you've completely hosed a 10,000 line project, and you know little about hardware till you've designed, built, and somehow troubleshot a complex board. We're still much like the blacksmith of old, who started his career as an apprentice, and who ends it working with apprentices, training them over the truth of a hot fire. Book learning is very important, but in the end we're paid for what we can do. In my career I've worked with lots of engineers, most with sheepskins, but many without. Both groups have had winners and losers. The non-degreed folks, though, generally come up a very different path, earning their engineering title only after years as a technician. This career path has a tremendous amount of value, as it's tempered in the forge of hands-on experience. Technicians are masters of making things. They are expert solderers - something many engineers never master. Since technicians spend their lives daily working intimately with circuits, some develop an uncanny understanding of electronic behavior. In college we learn theory at the expense of practical things. Yet I recently surveyed several graduate engineers and found none could integrate a simple function. None remembered much about the transfer function of a transistor. What happened to all of that hard-learned theory? Over the years I've hired many engineers with and without their bachelors, and have had some wonderful experiences with very smart, very hard working people who became engineers by the force of their will. Oddly, some of the best firmware folks I've worked with were English majors! Perhaps clear expression of ideas is universal, whether the language is English or C. We're in a very young field, where a bit of the anarchy of the Wild West still reigns. More so than in other professions we're judged on our ability and our performance. If you're competent, who cares what your scholastic record shows? But the world is changing. I'm constantly asked for advice about getting into this field, either into the electronics or firmware side. Many are looking for a shortcut, some way to substitute some practical experience for 4 or 5 years of college. Once that was quite possible. Today, though I always say the same thing: go to college. There are no shortcuts. Employers often feed resumes through acronym filters that discard those without academic credentials. Forty years ago, when I entered the field, returning Vietnam vets with lots of hands-on technician experience worked their way into engineering. Today that is almost unheard of. Having put three kids through college I know how expensive it is, and worry that the costs make school unaffordable for so many. MOOCs might be an answer, though the latest data is not promising. Still, the MOOC idea is very new. Always remember Leibson's law: it takes ten years for any disruptive technology to become pervasive. Steve limited his law to that of the design community, but I think it has broader scope. What's your take? |
||||
| Jobs! | ||||
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intents of this newsletter. Please keep it to 100 words.
|
||||
| Joke For The Week | ||||
Note: These jokes are archived at www.ganssle.com/jokes.htm. Beware of geeks bearing GIFs. |
||||
| Advertise With Us | ||||
Advertise in The Embedded Muse! Over 23,000 embedded developers get this twice-monthly publication. . |
||||
| About The Embedded Muse | ||||
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. |