|
|
|||
You may redistribute this newsletter for noncommercial purposes. For commercial use contact jack@ganssle.com. To subscribe or unsubscribe go to https://www.ganssle.com/tem-subunsub.html or drop Jack an email. |
|||
| Contents | |||
|
|||
| Editor's Notes | |||
How do you get projects done faster? Improve quality! Reduce bugs. This is the central observation of the quality movement that totally revolutionized manufacturing. The result is a win-win-win: faster schedules, lower costs and higher quality. Yet the firmware industry has largely missed this notion. Deming et al showed that you simply can’t bolt quality onto an extant system. But in firmware there’s too much focus on fixing bugs rather than getting it right from the outset. In fact it is possible to accurately schedule a project, meet the deadline, and drastically reduce bugs. Learn how at my one-day, fast-paced Better Firmware Faster class, presented at your facility. There's more info here. Thanks for the support for the Muse's new format! Without exception the email was very positive. Bob Paddock sent a link to Analog Devices application handbook. He also mentioned that they have most all of their seminar handbooks on-line here. The folks at The Microprocessor Report did a look-back at the state of the industry 25 years ago, and made this interesting observation: The tech of the time was the 386, which was built in 1.5 micron geometry with 275,000 transistors on a 103 mm2 die. Today's Ivy Bridge has 1.4 billion transistors at the 22 nm node on a die less than twice the size of the 386's. If the latter were built using the 22 nm node it would occupy just 0.02 mm2. Chuck Petras wrote about electronics education: The folks over at Digilent have been advancing the state of electronics learning
|
|||
| Quotes and Thoughts | |||
Documentation is a love letter that you write to your future self. - Damian Conway |
|||
| Tools and Tips | |||
Feel free to submit your ideas for neat ideas or tools you love or hate. Peter McConaghy noted that the URL in the last issue for Bray's Terminal no longer works. The correct one is https://sites.google.com/site/terminalbpp/ . |
|||
| What I'm Reading | |||
History of TSMC at the semiwiki. The Future of Connected-Device Security - Dave Kleidermacher's EDN article. Too Darned Big to Test - Dealing with huge systems. Is there a new theory of General Relativity that explains dark matter and dark energy? |
|||
| Methodology Tools | |||
In the embedded space, UML has a zero percent market share. In the embedded space, the Capability Maturity Model (CMM) has a zero percent market share (other than CMM1, which is chaos). The Shlaer-Mellor process tags right along at zero percent, as does pretty much every other methodology you can name. Rational Unified Process? Zilch. Design patterns? Nada. (To be fair, the zero percent figure is my observation from visiting hundreds of companies building embedded systems and corresponding with thousands of engineers. And when I say zero, I mean tiny, maybe a few percent, in the noise. No doubt an army of angry vendors will write in protesting my crude approximation, but I just don’t see much use of any sort of formal process in real embedded development). There’s a gigantic disconnect between the typical firmware engineer and methodologies. Why? What happens to all of the advances in software engineering? Mostly they’re lost, never rising above the average developer’s horizon. Most of us are simply too busy to reinvent our approach to work. When you’re sweating 60 hours a week to get a product out the door it’s tough to find weeks or months to institute new development strategies. Worse, since management often views firmware as a necessary evil rather than a core competency of the business they will invest nothing into process improvement. But with firmware costs pushing megabucks per project even the most clueless managers understand that the old fashioned techniques (read: heroics) don’t scale. Many are desperate for alternative approaches. And some of these approaches have a lot to offer; properly implemented they can great increase product quality while reducing time to market. Unfortunately, the methodology vendors do a lousy job of providing a compelling value proposition. Surf their sites; you’ll find plenty of heartwarming though vague tales of success. But notably absent are quantitative studies. How long will it take for my team to master this tool/process/technique? How much money will we save using it? How many weeks will it shave off my schedule? Without numbers the vendors essentially ask their customers to take a leap of faith. Hard-nosed engineers work with data, facts and figures. Faith is a tough sell to the boss. Will UML save you time and money? Maybe. Maybe even probably, but I’ve yet to see a profit and loss argument that makes a CEO’s head swivel with glee. The issues are complex: tool costs are non-trivial. A little one-week training course doesn’t substitute for a couple of actual practice projects. And the initial implementation phase is a sure productivity buster for some block of time. Developers buy tools that are unquestionably essential: debuggers, compilers, and the like. Few buy methodology and code quality products. I believe that’s largely because the vendors do a poor job of selling – and proving – their value proposition. Give us an avalanche of successful case studies coupled with believable spreadsheets of costs and time. Then, Mr. Vendor, developers will flock to your doors, products will fly off the shelves, and presumably firmware quality will skyrocket as time-to-market shrinks. What do you think? Turned off – or on – by methodology tools? Why? |
|||
| Battle of the CPUs: Cortex M4 vs. M0 | |||
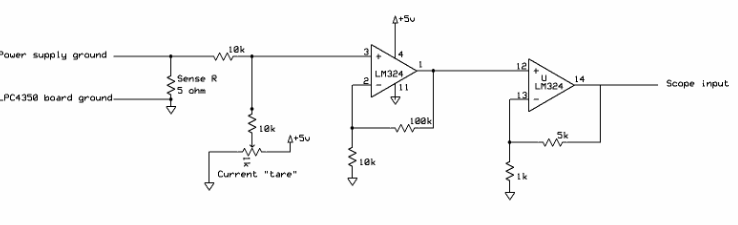
In the last few years the industry has increasingly embraced the notion of using multiple processors, often in the form of multicore. Though symmetric multiprocessing - the use of two or more identical cores that share memory - has received a lot of media attention, many embedded systems are making use of heterogeneous cores. A recent example is ARM's big.LITTLE approach, which is specifically targeted to smart phones. A big Cortex-A15 processor does the heavy lifting, but when computational demands are slight it goes to sleep and a more power-frugal A7 runs identical code. It's challenging to measure the difference in power used by the cores as there's no way to isolate power lines going to the LPC4350 on the Hitex board I was using. The board consumes about 0.25 amp at five volts, but most of that goes to the memories and peripherals. To isolate the LPC4350's changing power needs I put a 5 ohm resistor in the ground lead to the board, and built the circuit in figure 1. The pot nulls out the nominal 0.25 amp draw, and multiplies any difference from nominal by 50. The output is monitored on an oscilloscope.
Figure 1: Current monitor circuit The cores run a series of tests, each designed to examine one aspect of performance. The cores run the tests alternately, going to sleep when done. Thus, after initialization only one core is ever active at a time. When running a test the core sets a unique GPIO bit which is monitored on the scope to see which core is alive, and how long the test takes to run. One of those GPIO bits is assigned, by the board's design, to an LED. I removed that so its consumption would not affect the results. All of the tests use a compiler optimization level of -O3 (the highest). The tests are identical on each processor, with one minor exception noted later. Figure 2 is an example of the data. The top, yellow, trace is the M4's GPIO bit, which is high when that processor is running. The middle, green, trace is the bit associated with the M0. Note how much faster the M4 runs. The lower, blue, trace is the amplified difference in consumed power. I attribute the odd waveform to distributed capacitance on the board, and it's clear that the results are less quantitative than one might wish. But it's also clear the M4, with all of its high-performance features, sucks more milliamps than the M0. So the current numbers I'll quote are indicative rather than precise, sort of like an impressionistic painting.
Figure 2: The FIR test results The first test put both CPUs to sleep, which reduced the board's power consumption by about 10 ma; that is, both CPUs running together consume somewhere around 10 ma. First impression: this part is very frugal with power. In test 0 the processors take 300 integer square roots, using an algorithm from Math Toolkit for Real-Time Programming by Jack Crenshaw. Being integer, this algorithm is designed to examine the cores' behavior running generic C code. The M4 completes the roots in 1.842 msec, 21 times faster to the M0's 38.626 msec, but the M0 uses only a quarter of the current. The next test ran the same algorithm using floating point. The M4 shined again, showing off its FPU, coming in 12 times faster than the M0 but with twice the power-supply load. There's considerable non-FPU activity in that code; software that uses floating point more aggressively will see even better numbers. Test 3 also took 300 floating point square roots, and is the only one where the code varied slightly between cores. On the M4 it uses the __sqrtf() intrinsic instead of the M0's conventional C function sqrt(). The former invokes the FPU's VSQRT instruction, and that CPU just screamed with 174 times the performance of the M0. It was so fast the power measurements were completely swamped by the board's capacitance. One of the Cortex-M4's important feature is its SIMD instructions. To give them a whirl I implemented an FIR algorithm that made use of the SMLAD SIMD instruction. Since the M0 doesn't have this I used the SMLAD macro from ARM's CMSIS library that requires several lines of C. Not surprisingly, the M4 blew the M0 out of the water, completing 20 executions of the filter in 5.15 msec, 10 times faster than the M0 and for 9 times as many milliamps. But I was surprised the results weren't even better, considering how much the M0 has to do to emulate the M4's single-cycle SMLAD. So I modified the program with a SIMD_ON #define. If TRUE, the code ran as described. If FALSE, the SMLADs were removed and replaced by simple assignment statements. The result: the M4 still ran in 5.15 msec. There was no difference, indicating that essentially all of the time was consumed in other parts of the FIR code. In other words, code making heavier use of the SIMD instructions will run vastly faster. One note: in many cases the M4 consumed less power than the M0, despite the higher current consumption, since the M4 ran so much faster than the M0. The M4 was asleep most of the time. However, in many systems a CPU has to be awake to take care of routine housekeeping functions. It makes little sense to use the M4 for these operations when the M0 can do them with a smaller power budget, and even handle some of the more complex tasks at the same time. Though the LPC43xx is positioned as a fast processor with extensions for DSP-like applications, coupled with a smaller CPU for taking care of routine control needs, it's also a natural for deeply embedded big.LITTLE-like situations where a dynamic tradeoff between speed and power makes sense. The IDE was from Keil, which has pretty good support for debugging two CPUs over single a shared JTAG connection. I found it was quite functional, though it took a lot of clicking around to go back and forth between cores. The flashing of windows during each transition was a bit annoying. A better solution would be two separate IDEs sharing that JTAG instead of a single shared window, especially for those of us running multiple monitors. |
|||
| Doxygen | |||
| Stephen Phillips sent in this:
I remember sending you an email circa 7-18-2007 regarding the use of Doxygen and its usefulness for documenting code. Now 5 years later, here are my observations:
|
|||
| Jobs! | |||
Let me know if you’re hiring embedded engineers. No recruiters please, and I reserve the right to edit ads to fit the format and intents of this newsletter. Please keep it to 100 words.
|
|||
| Joke For the Week | |||
Note: These jokes are archived at www.ganssle.com/jokes.htm. This is from Agustín Ferrari: A young engineer was leaving the office at 3.45 p.m. when he found the Acting CEO standing in front of a shredder with a piece of paper in his hand. |
|||
| About The Embedded Muse | |||
The Embedded Muse is Jack Ganssle's newsletter. Send complaints, comments, and contributions to me at jack@ganssle.com. The Embedded Muse is supported by The Ganssle Group, whose mission is to help embedded folks get better products to market faster. |