

On Wait States
Summary: ST's ART accelerator gives near-zero wait state operation out of slow flash.
Regular readers know I'm a big fan of the Cortex-M family of MCUs. A wide variety of vendors have brought 32 bit processing to the low end of the market, sometimes for astonishing sub-dollar prices. In some cases these parts even have hardware floating point and SIMD instructions.
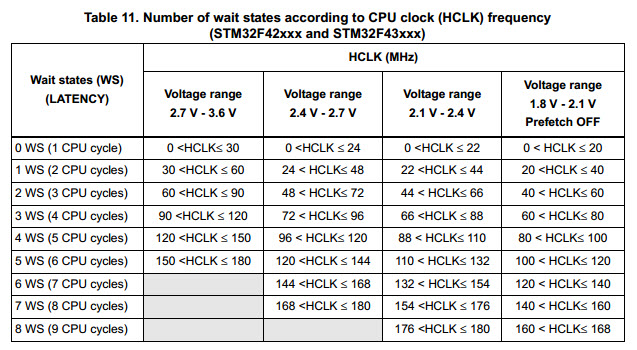
But there is a dark secret to some of these devices. They all sport flash, and programs can run from that memory. But flash is generally slow. Consider ST's STM32F4 which can run at 168 MHz - that's 6 ns/instruction! With some parts (as we'll see, not the ST device) increasing clock rates means adding wait states when running from flash, so there may be little performance improvement gained by cranking up the clock.
The STM32F4 user manual (http://www.st.com/st-web-ui/static/active/en/resource/technical/document/reference_manual/DM00031020.pdf) shows the problem:
One partial solution that's often employed is cache. The most-recently-used instructions are stored in a zero-wait state cache so are immediately available when needed. But that kind of memory is real-estate hungry, so is always tiny. Figure on the order of a few to 32KB or so. Most real programs are constantly banging into cache misses, each of which stalls the CPU as it injects wait states while pausing for the slow flash to catch up. Cache also makes execution time completely unpredictable, which is a major concern for many real-time systems.
ST takes a unique approach. First, each flash read is 128 bits wide - a single fetch brings in 16 bytes of memory. Given that instructions are 16 or 32 bits, the average read brings in around 6 instructions, all at the cost of one set of wait states (from the table above). Absent this approach figure on around six times as many wait states. That's a pretty startling speedup.
(It's not clear to me if interrupts count, but one would think they are. If so, that's could be a huge improvement in ISR performance for frequently-invoked interrupts).
What about the instructions after those 16 bytes? They run at zero wait states, because the MCU prefetches another 128 bits while executing the cached instructions.
This is the architecture:
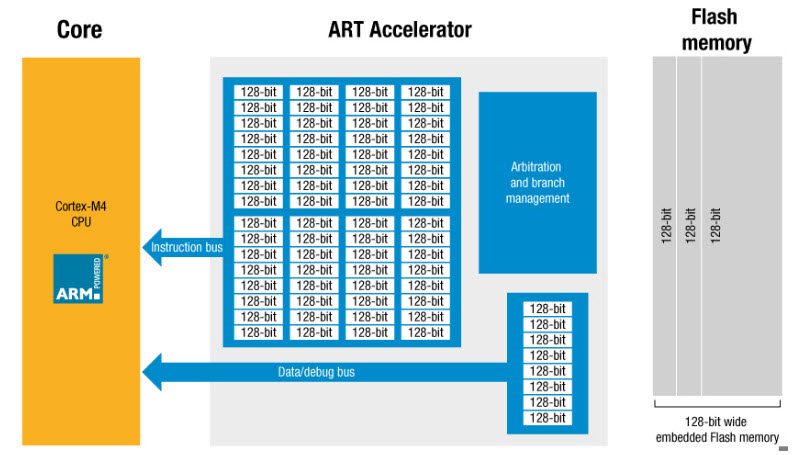
"ART" is ST's acronym for Adaptive Real-Time Memory Accelerator.
The efficacy of this very nice approach will be correlated with the density of branches. More branches means the cache fills faster and CPU stalls will increase.
Here's a snippet of the compiled code from a program I wrote for a Cortex M3 some time ago. It's a little strange-looking as it was designed to test the speed of the MCU in doing certain kinds of math:
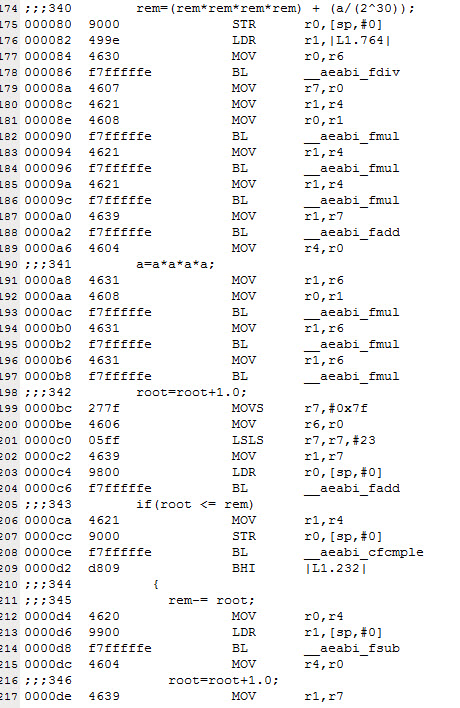
This is doing a bit of floating point math, and you can see a lot of branches to the floating point library. But there are only a few distinct calls; all of those to __aeabi_fmul will run very fast, at zero wait states, after the first call to it. The cache will fill relatively slowly. And, the STM32F4 has hardware floating point so the compiler will insert instructions in-line rather than calls to the library.
Obviously, different code will exhibit differing branch densities. But this is an interesting way to overcome slow flash.
What about your processor? How does it deal with flash's inherent slowness?
Published May 19, 2015