

Down With Productivity
Summary: How to kill a software team's productivity, in one easy lesson.
What's the best way to kill the productivity of a software engineering team?
Work on a large project.
There's a lot of research that shows as projects grow in size, individual programming productivity collapses. Consider this IBM data:
 Schedule growth on this chart is driven by two factors. First, the projects are getting bigger. More lines of code.
Schedule growth on this chart is driven by two factors. First, the projects are getting bigger. More lines of code.
Second, as the column on the right shows, individual programmer productivity is going down as the size of the project increases. There's an order of magnitude collapse in the amount of code each programmer generates per month. An order of magnitude - that's an enormous hit.
The Constructive Cost Models (COCOMO) are well-known methods for estimating software schedules. (While COCOMO is well-known it's little used. COCOMO II has 15 coefficients that must be adjusted to a particular team.) The models are complex, but they essentially say that the schedule is proportional to the size of the program in KLOC raised to some exponent x, where x is greater than one. Obviously, that implies, as the IBM data shows, an exponential collapse in productivity versus size.
(I'm not a fan of COCOMO as it's very hard to estimate the number of lines of code that go into a project. But it's useful for shining light on the problems of scheduling).
What causes this effect? Bigger programs are harder to understand, have more interfaces, and other technical issues. But there's a people effect, too.
If there's one person on a project, there are zero communications channels between team members. It's all in that person's head, and, if not bipolar, there's no discussions to be had. The developer just rolls up the metaphorical sleeves and gets to work.
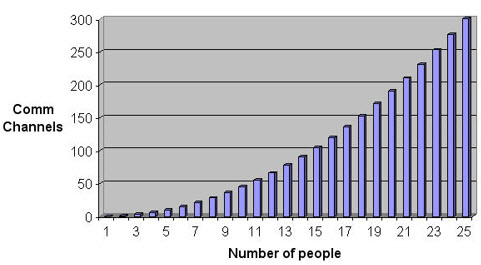
If there are two on the team, there's one comm link between them. It turns out that if n is the number of developers on a project, the number of communications channels between them is n(n-1)/2.
To a first approximation that's not far off from n**2. With a big team we're all so busy talking to each other there's no time to write code. There's all those emails that have to be answered. The meetings. More meetings. Status reports. Then there's a chance to squeak out a line of code before another meeting is called.
Here's that formula graphically:
It would be nice to conclude the secret is to keep projects small, but some, like a mobile phone, are intrinsically huge. A phone can easily have ten million lines of code.
Big projects will always shoulder a productivity tax, but there are ways to ameliorate it, to effectively find big deductions for the system's 1040. All involve partitioning, breaking a system up into small parts. Each part is done by a small team at a high level of productivity. Keep interfaces small, clean, and well-documented to minimize the inter-team communications.
Not long ago I was called into a troubled project. 700 developers were working on a single executable. Years late, it was shipping, but was bug-ridden and almost impossible to maintain. New features were problematic to implement. Ironically, one of their competitors had a similar product done by a team half as big. The main difference? Well, there were two big factors.
The big, troubled team was completely dispirited. They knew things were desperate, but had been so for so long most felt hopeless.
In addition, the smaller group had done a fabulous partitioning scheme. Instead of one microprocessor there were many (mostly virtual on an ASIC). With many CPUs individual executables were small and built by small sub-groups. Some of the processors had very-carefully-thought out independently-running processes; each of those processes were in turn done by small groups.
The lesson is that many small tasks get done much faster than a few big ones.
Published October 16, 2015