

By Jack Ganssle
Software For Dependable Systems
The average developer reads one trade journal a month, and but a single technical book a year. This implies that most of us feel the industry isn't changing much, or that we don't care to stay abreast of latest developments. I shudder to think the latter, and know for a fact the former just isn't true.
Another excuse is that too many tomes are so dry that even a gallon of Starbuck's most potent brew won't keep the eyes propped open. And sometimes wading through hundreds of pages yields very little new insight.
But recently I came across one of the most thought-provoking software books I've read in a long time. At 131 pages it's not too long, and a PDF is available on the web (http://www.nap.edu/catalog.php?record_id=11923). Titled "Software for Dependable Systems - Sufficient Evidence?", it was edited by Daniel Jackson, Martyn Thomas, and Lynettte Millett, and is the product of the Committee on Certifiably Dependable Software Systems. Not only is this volume utterly fascinating, it's incredibly well-written. I had trouble putting it down.
I often rant about poor quality code haunting us and our customers. Yet software is one of the most perfect things humans have created. Firmware, once shipped, averages a few bugs per thousand lines of code. But software is also one of the most complex and fragile of all human creations. In school, and in most aspects of life a 90% is an A. In software a 99.9% is, or may be, an utter disaster.
Perfection is not a human trait. Software is made by people. So can software ever be perfect?
Maybe not. But there's no question it has to meet standards never before achieved by Homo sapiens. Software size has followed a trajectory parallel to Moore's Law, and complexity grows faster than size. The projects we'll be cranking out in even a decade will dwarf anything made today, and in many cases will be in charge of much more dangerous systems than now. Think steer-by-wire in hundreds of millions of cars, or even autonomous driving down route 95.
"Software for Dependable Systems" tackles the question of how can we know if a system, and in particular the software, is dependable? When we let code loose on an unsuspecting public, how much assurance can we offer that the stuff will run correctly, all of the time?
Currently, engineers building safety-critical applications typically use standards like DO-178B or IEC 61508 to guide the development process. These are prescriptive approaches that mandate certain aspects of how the software gets built. For instance, at the highest level of DO-178B MC/DC (Modified Condition/Decision Coverage) testing is required. MC/DC hopes to ensure that the code is totally tested. Seems like a great idea, but there's little evidence about how effective it really is.
The agile community promotes people over process. Most certification standards take the opposite tack. "Software for Dependable Systems" stresses the importance of both process and people. But they go further, and express the conviction that software will always be of unknown quality - which is scary for a safety-critical application - unless there's more positive proof it is indeed correct.
The book makes a number of suggestions, all of which are valuable. But its most important message is a three-pronged strategy about evaluating the system. Note the use of the word "system;" continually stressed is the idea that software does not exist in isolation, it's part of a larger collection of components, both hardware and human. A program that functions perfectly is utterly flawed if it demands superhuman performance from the user - or even human-level performance in a high stress situation. I was reminded David Mindell's "Digital Apollo" which describes how the spacecraft, ground controllers and astronauts were a carefully designed single integrated system, and one of the biggest problems faced by the engineers was balancing the role of each of those components in the larger Apollo structure.
First prong: make explicit dependability claims. Saying "the system must not crash" is meaningless. Surely a crash is reasonable if power is removed, or someone takes an ax to the unit. Dependability claims are framed in the environment in which the system is expected to work. An IC is specified to work only within certain temperature and humidity limits, for instance. A dependability claim may state a range of inputs, certain user behavior, or other aspects of the unit's operational environment.
This is very akin to the Common Criteria for security in which seven Evaluation Assurance Levels are specified. At level one, well, the vendor basically showed up for the meeting. At 5 and above the code must be semi-formally or formally proven to be correct. But those levels are based on protection profiles, which are collections of security claims. Some flavors of Windows have been evaluated to EAL4+, which sounds great! But that's against the Controlled Access Protection Profile whose security claims are very weak indeed, and basically state that everyone who has access to the computer are nice guys with no hostile intent. Of course, an Internet connection means all of the vermin of the world have access. Others, like the Separation Kernel Protection Profile, make much more demanding claims against which the EAL evaluations are applied.
Next, provide concrete evidence that each dependability claim has been met. These "dependability cases" are arguments constructed in any number of ways to prove a particular claim. Testing might be part of such a case, complemented with, perhaps, formal proofs, analysis, appeals at times to the process used, etc.
Critically important is that the dependability cases be accessible to more than just the developers; ideally, they should be constructed in such a fashion that others, perhaps customer or regulators, can follow the reasoning. The authors suggest that the cost to review a dependability case should be at least an order of magnitude cheaper than the cost to construct it.
It will generally be much too expensive to create dependability cases post-development (i.e., shoehorn quality into an extant system), so constructing these cases is a process that will underlie all aspects of development, and may even change the requirements. Above all, throughout the effort the chain of evidence must be maintained to provide final proof of the system's correctness.
Finally, expertise is demanded. Process and people. Experts in software engineering and the problem's domain will create the system, the claims, and the dependability cases.
This book is not a prescriptive document; there's no step by step guide to doing anything. That's a bit frustrating for a practicing engineer, but the committee does not want to limit processes teams may use. Expertise insures that when we balance development approaches we select those that will lead to dependable systems.
The book does include a list of industry best practices. That section leads with a long treatise on the value of simplicity. Here's where expertise really comes into play, as any idiot can add complexity to a design. It takes real skill to invent a design that glimmers in its elegance and simplicity. Further, a simple design eases the task of constructing a dependability case.
What about warranties? "No software should be considered dependable if it is supplied with a disclaimer that withhold the manufacturer's commitment to provide a warranty or other remedies for software that fails to meet its dependability claims." Alas, few packages make any dependability claims, and, worse, EULAs are just the opposite of a guarantee as they disclaim all liability and rarely even warrant that the software will work in any fashion.
Do I wish the book was more of an idiot's guide? You betcha. But the committee took the right approach. Not every application will profit from one set of guidelines. I view this document as a critical bit of reasoning and a manifesto on which we can all build. Is this a philosophy only for safety-critical systems? Yes and no. The cost to develop the evidence that dependability claims have been satisfied will be significant. A mobile phone might not need such dependability.
Or maybe it will. Consider the tales of phones bursting into flames. Injure someone, and the cost to the company could be much higher than that of building evidence of dependability. If a software problem prevents someone from calling 911 in an emergency, the courts could bankrupt the company. In 1980 the Las Vegas MGM Grand Hotel burned. 85 people died. There was no sprinkler system in the casino and restaurants because the installation of such would have cost $200,000. Eventually $223 million was paid out in damages. Cheaper is often much more costly than what initially seems expensive.
The authors suggest using a "safe" language, and they explicitly recommend against the use of C. SPARK is suggested as an acceptable alternative as there are no dark holes in SPARK, and the code can be statically tested.
SPARK is a subset of Ada (any Ada compiler will translate it properly) developed and supported by Praxis High Integrity Systems (http://praxis-his.com/). But developers also place contracts in the comments (see my March, April and May 2007 articles about design for contract) that can be checked by a static analyzer. For instance, the following code has contracts that tell the analyzer what to expect on entry and exit from procedure Inc:
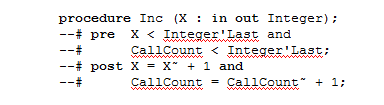
(Code courtesy of Praxis High Integrity Systems).
All this extra work will kill productivity, don't you think?
Actually, no. Several studies have shown that the use of SPARK and the methods Praxis advocates accelerate delivery and reduces (dramatically) bug rates. For instance, a joint NSA/Praxis/SPRE project named Tokeneer (full report and source code here: http://www.adacore.com/home/products/sparkpro/tokeneer/) resulted in about 10K lines of code and consumed 260 person-days, a productivity rate far higher than most commercial projects. That includes the time to generate hundreds of pages of documents.
A total of 54 defects were found during development (that includes specification errors, coding mistakes, etc.), and of those 36 were "minor," meaning spelling errors and the like.
18 important bugs in 10KLOC. Though Praxis' "correctness by construction" approach does involve more up-front work, it shrinks schedules by removing most of the debugging.
But wait, there's more: The SPARK tools are available under the GPL license with the option of commercial support from Praxis.
The Praxis folks have a strong alliance with AdaCore, with whom I met at the Boston ESC. I was stunned by the announcement of the latter's High-Integrity Edition for MILS. As mentioned above, high EAL levels require various kinds of excruciatingly-tedious proofs of correctness, which has historically been a hugely expensive process that can take years. AdaCore's new offering uses the SPARK correctness by construction approach, plus certified runtimes from AdaCore, to in large part automatically generate the formal verifications for EAL5 to 7. There's still plenty of paperwork required to satisfy the Common Criteria's process, but the hard part can be done automatically. Fabulous code. Delivered faster. With a certification-ready set of formal proofs. Wow!
The demand for high-quality systems will grow, probably explosively. There are a lot of great ideas circulating that lead to security and dependability. The tools and techniques needed have been proven commercially. To mangle Bob Dylan, you don't need to be a weatherman to see which way the wind will blow.
Published October 1, 2009