

By Jack Ganssle
Published in Embedded Systems Design, March 2008
Multicore: Hype or Reality?
For many years processors and memory evolved more or less in lockstep. Early CPUs like the Z80 required a number of machine cycles to execute even a NOP instruction. At the few MHz clock rates then common, processor speeds nicely matched EPROM and SRAM cycle times.
But for a time memory speeds increased faster than CPU clock rates. The 8088/6 had a prefetcher to better balance fast memory to a slow processor. A very small (4 to 6 bytes) FIFO isolated the core from a bus interface unit (BIU). The BIU was free to prefetch the most-likely needed next instruction if the core was busy doing something that didn't need bus activity. The BIU thus helped maintain a reasonable match between CPU and memory speeds.
Even by the late 80s processors were pretty well matched to memory. The 386, which (with the exception of floating point instructions) has a programmer's model very much like Intel's latest high-end offerings, came out at 16 MHz. The three-cycle NOP instruction thus consumed 188 nsec, which partnered well with most zero wait state memory devices.
But clock rates continued to increase while memory speeds started to stagnate. The 386 went to 40 MHz, and the 486 to over 100. Some of the philosophies of the reduced instruction set (RISC) movement, particularly single-clock instruction execution, were adopted by CISC vendors, further exacerbating the mismatch.
Vendors turned to Moore's Law as it became easier to add lots of transistors to processors to tame the memory bottleneck. Pipelines sucked more instructions on-chip, and extra logic executed parts of many instructions in parallel.
A single-clock 100 MHz processor consumes a word from memory every 10 nsec, but even today that's pretty speedy for RAM and impossible for flash. So on-chip cache appeared, again exploiting cheap integrated transistors. That, plus floating point and a few other nifty features meant the 486's transistor budget was over four times as large as the 386.
Pentium-class processors took speeds to unparalleled extremes, before long hitting two and three GHz. 0.33 nsec memory devices are impractical for a variety of reasons, not the least of which is the intractable problem of propagating those signals between chip packages. Few users would be content with a 3 GHz processor stalled by issuing 50 wait states for each memory read or write, so cache sizes increased more.
But even on-chip, zero wait state memory is expensive. Caches multiplied, with a small, fast L1 backed up by a slower L2, and in some cases even an L3. Yet more transistors implemented immensely complicated speculative branching algorithms, cache snooping and more, all in the interest of managing the cache and reducing inherently-slow bus traffic.
And that's the situation today. Memory is much slower than processors, and has been an essential bottleneck for fifteen years. Recently CPU speeds have stalled as well, limited now by power dissipation problems. As transistors switch, small inefficiencies convert a tiny bit of Vcc to heat. And even an idle transistor leaks microscopic amounts of current. Small losses multiplied by hundreds of millions of devices means very hot parts.
Ironically, vast numbers of the transistors on a modern processor do nothing most of the time. No more than a single line of the cache is active at any time, most of the logic to handle hundreds of different instructions stands idle till infrequently needed, and page translation units that manage gigabytes handle a single word at a time.
In the supercomputing world similar dynamics were at work. GaAs logic and other exotic components drove clock rates high, and liquid cooling kept machines from burning up. But long ago researchers recognized the futility of making much additional progress by spinning the clock rate wheel ever higher, and started building vastly parallel machines. Most today employ thousands of identical processing nodes, often based on processors used in standard desktop computers. Amazing performance comes from massively parallelizing both the problems and the hardware.
To continue performance gains desktop CPU vendors co-opted the supercomputer model and today offer a number of astonishing multicore devices, which are just two or more standard processors assembled on a single die. A typical configuration has two CPUs, each with their own L1 cache. Both share a single L2, which connects to the outside world via a single bus. Embedded versions of these parts are available as well, and share much with their desktop cousins.
The Problem With SMP
Symmetric multiprocessing has been defined in a number of different ways. I chose to call a design using multiple identical processors which share a memory bus an SMP system. Thus, multicore offerings from Intel, AMD, and some others are SMP devices.
SMP will yield performance improvements only (at best) insofar as a problem can be parallelized. Santa's work cannot be parallelized (unless he uses his gives each elf a sleigh), but delivering mail order products keeps a fleet of UPS trucks busy and efficient.
Amdahl's Law gives a sense of the benefit accrued from using multiple processors. In one form it gives the maximum speedup as:
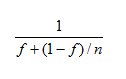
where f is the part of the computation that can't be parallelized, and n is the number of processors. With an infinite number of cores, assuming no other mitigating circumstances, figure 1 shows (on the vertical axis) the possible speedup versus (on the horizontal axis) the percentage of the problem that cannot be parallelized.
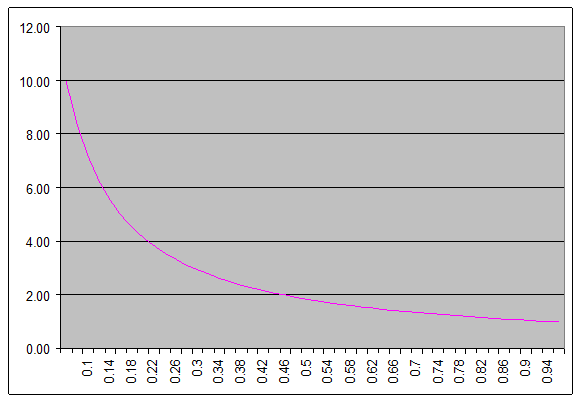
Figure 1: Possible speedup versus percentage of the problem that cannot be parallelized, assuming an infinite number of cores.
The Law is hardly engraved in stone as there are classes of problems called "embarrassingly parallel" where huge numbers of calculations can take place simultaneously. Supercomputers have long found their niche in this domain, which includes problems like predicting the weather, nuclear simulations, and the like.
The crucial question becomes: How much can your embedded application benefit from parallelization? Many problems have at least some amount of work that can take place simultaneously. But most problems have substantial interactions between components that must take place in a sequence. It's hard at best to decide at the outset, when one is selecting the processor, how much benefit we'll get from going multicore.
Marketing literature from multicore vendors suggest that a two core system can increase system performance from 30 to 50% (for desktop apps; how that scales to embedded systems is another question entirely, one that completely depends on the application). Assuming the best case (50%) and working Amdahl's Law backwards one sees that the vendors assume a third of the PC programs can be parallelized. That's actually a best, best, case as a PC runs many different bits of software at the same time, and could simply split execution paths by application. But, pursuing this line of reasoning, assuming the dramatic 50% speed improvement comes from running one program, the Law shows that with an infinite number of processors the best one could hope for would be a 3x performance boost (excepting the special case of intrinsically parallel programs).
Then there's the bus bottleneck.
Each of the twins in a dual-core SMP chip has its own zero wait state cache, which feeds instructions and data at sizzling rates to the CPU. But once off L1 they share an L2, which though fast, stalls every access with a couple of wait states. Outside of the L2, a single bus serves two insanely high-speed processors that have ravenous appetites for memory cycles, cycles slowed by so many wait states as to make the processor clock rate for off-chip activity almost irrelevant.
And here's the irony: a multi-GHz CPU that can address hoards of GB of memory, that has tens of millions of transistors dedicated to speeding up operations, runs mind numbingly fast only as long as it executes out of L1, which is typically a microscopic 32 to 64 KB. PIC-sized. Run a bigger program, or one that uses lots of data, and the wait state logic jumps on the brakes
A couple of Z80s might do almost as well.
In the embedded world we have more control of our execution environment and the program itself than in a PC. Some of the RTOS vendors have come up with clever ways to exploit multicore more efficiently, such as pinning tasks to particular cores. I have seen a couple of dramatic successes with this approach. If a task fits entirely within L1, or even spills over to L2, expect tremendous performance boosts. But it still sort of hurts ones head - and pocketbook - to constrain such a high-end CPU to such small hunks of memory.
Any program that runs on and off cache may suffer from determinism problems. What does "real time" mean when a cache miss prolongs execution time by perhaps an order of magnitude or more? Again, your mileage may vary as this is an extremely application-dependent issue, but proving a real-time system runs deterministically is hard at best. Cache, pipelines, speculative execution, and now two CPUs competing for the same, slow, bus all greatly complicate the issue. By definition, a hard real time system that misses a deadline is as broken as one that has completely defective code.
Multicore does address a very important problem, that of power consumption. Some vendors stress that their products are more about MIPs/watt than raw horsepower. Cut the CPU clock a bit, double the number of processors, and the total power needs drop dramatically. With high-end CPUs sucking 100 watts or more (at just over a volt; do the math and consider how close that is to the amps needed to start a car), power is a huge concern, particularly in embedded systems. Most of the SMP approaches that I've seen, though, still demand tens of watts, far too much for many classes of embedded systems.
One wonders if a multicore approach using multiple 386s stripped of most of their fancy addressing capability and other bus management features, supported by lots of "cache", or at least fast on-board RAM, wouldn't offer a better MIPS/watt/price match, at least in the embedded space where gigantic applications are relatively rare.
Finally, the holy grail of SMP for thirty years has been an auto-parallelizing compiler, something that can take a sequential problem and divide it among many cores. Progress has been made, and much work continues. But it's still a largely unsolved problem that is being addressed in the embedded world at the OS level. QNX, Green Hills, and others have some very cool tools that partition tasks both statically and dynamically among cores. But expect new sorts of complex problems that make programming a multicore system challenging at best.
Conclusion
While this rant may be seen as some to be completely dismissive of multicore that's not the case at all; my aim is to shine a little light into the marketing FUD that permeates multicore, as it does with the introduction of any new technology. Multicore processors are here to stay, and do offer some important benefits. You may find some impressive performance gains by employing SMP, depending upon your specific application. Do see David Kleidermacher's article about it at http://embedded.com/design/205203908.
Most of my complaints disappear when each core runs code from its own memory space. Tensilica has some customers getting astonishing performance gains using this approach. Picochip's results are impressive as well (see http://www.insidedsp.com/Articles/tabid/64/articleType/ArticleView/articleId/228/Default.aspx for a recent benchmark). But that's not SMP and is a completely different discussion.
As always, do a careful analysis of your particular needs before making a possibly expensive foray into a new technology.